Tacotron: Towards End-to-End Speech Synthesis 자세히 설명
Tacotron, text-to-speech 설명
CBHG
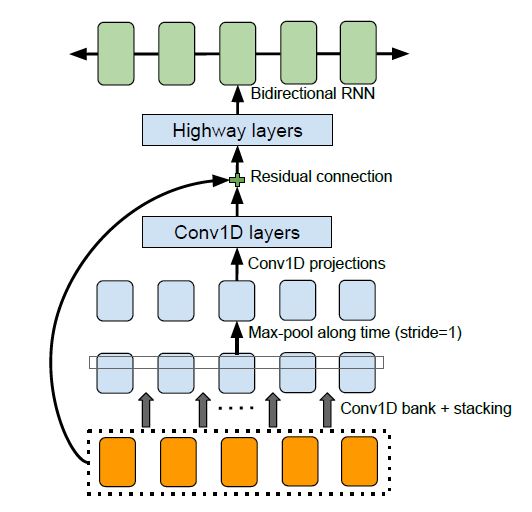
convolutional 1-D filters, bank, hightway network, Bidirectional GRU로 이루어져있다.
부분적인 특징을 잡아내는데 유용한 CNN과 연속적인(sequential)데이터를 생성하기 좋은 RNN의 특징을 모두 활용하였다. 몇 초짜리의 발화(utterance) 데이터를 정해진 크기만큼 순차적으로 학습하고, 목소리 특징을 뽑아내는(CNN)을 동시에, 뽑혀진 부분 특징을 전체적으로 보면서 결과를 만들어 낸다.(RNN)
- 입력, Convolution Bank
CBHG에 입력으로 들어가게 되면 시퀀스 타임 스텝 축을 따라 1D convolution이 이루어지는데 이때 Convolution kernel이 여러 사이즈를 가진 여러 종류로 사용되게 된다.
Convolution Bank는 encoder에서 kernel 사이즈를 1~16까지 16개를 사용하게된다.(decoder의 PostNet에 사용되는 CBHG의 경우는 kernel 사이즈를 1~8까지 8개를 사용)
각각의 kernel을 이용하여 1D Convolution을 수행 한 후에 그 결과들을 Concat하여 다음 단계로 넘기게 된다. 한편 본 논문에서는 Convolution마다 Batch normalization을 수행한다고 한다.
- Max Pooling
Convolution Bank를 거친 후에는 다시 타임 스텝의 축을 따라 Max Pooling이 수행되게 된다.(local invariance(지역 불변성)를 증가시키기 위해 시간으로 Max Pooling)
이때 stride를 1로 사용하여 원래 time resolution을 보존한다.
- 1D convolution, Residual Connection
이후 고정된 너비의 1D convolution을 거친 이후 입력 레이어와 Residual Connection을 만들고 multi-layer Highway network로 넘어간다.(high level 특성을 추출하기 위해)
- Highway layer
Highway Network는 Gating 구조를 사용하는 Residual 네트워크이다. Residual 네트워크는 간단하게 다음과 같이 표현할 수 있다. \(Residual(x) = R(x) + x\) 입력과 출력을 더하는 방식의 Residual구조는 Vanish Gradient 문제를 해결하기 위해 고안된 구조이다.
Highway Network에서는 Gating을 통해 현재 Residual의 비율을 모델이 자동으로 어느 정도로 할 지 결정하게끔 구성한다. \(Highway(x)=T(x)*H(x) + (1-T(x))*x\) 이때 T(x)를 Transform Gate라고 하는데 output이 input에 대하여 얼마나 변환되고 옮겨졌냐를 표현한다, 여기서 T(x)의 Bias는 무조건 -1과 같은 음수로 초기화 해야한다. 왜냐하면 학습 초기에 장기적인 시간 종속성을 연결하는데 도움이 되기때문이다.
HighwayNetwork 설명 블로그1 HighwayNetwork 설명 블로그2
- Bidirectional RNN
Highway 네트워크를 거친 이후에는 Bidirection GRU를 거치게 된다. 여기서 Forward 시퀀스와 Backward 시퀀스를 Concat하여 결국 텍스트를 잘 나타내는 숫자 벡터, 텍스트 임베딩을 출력한다.