NEURAL MACHINE TRANSLATION BY JOINTLY LEARNING TO ALIGN AND TRANSLATE 요약,정리
Seq2Seq, Attetion, MACHINE TRANSLATION
English to Korean
I love you = 난 널 사랑해
번역하는데 가장 최고의 방법은?
‘I love you’ 를 ‘난 널 사랑해’로 기계번역을 하고 싶다.
Word to Word translation?
가장 간단한 방법으로는 각 단어를 단어로 번역한다.(Word to Word translation)
| Input | — | prediction |
|---|---|---|
| I | ==> | 난 |
| love | ==> | 사랑해 |
| you | ==> | 널 |
| I love you | ==> | 난 사랑해 널 |
하지만 정답은 ‘난 널 사랑해’ 이다.
문제점 1 :English and Korean has different word order
이러한 문제가 발생되는 이유는 영어는 S.V.O Language이고 한국어는 S.O.V Language이기 때문이다. 어순이 다르기 때문이다.
문제점 2: word to word translation is output always have same word count with input, while it should not
How are you ? = 잘 지내?
3 words —–> 2 words
단어별로 번역을 하게되면 3개의 단어로 이루어진 문장은 3개의 단어로 이루어진 문장을 내뱉게 된다.
따라서 단어별로 번역하는 방법은 좋은 방법이 아니다.
RNN을 이용
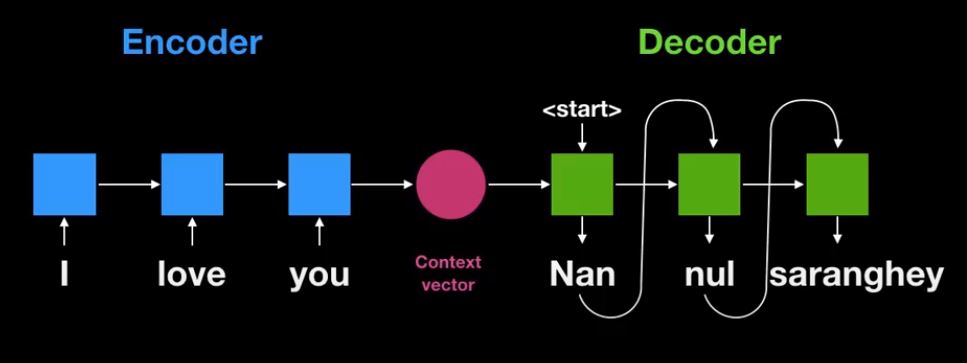
각 RNN cell에 ‘I’, ‘love’, ‘you’가 들어간다.
결과적으로 최종 RNN cell의 state는 ‘I love you’라는 information을 함축하고 있다. 이 벡터를 Context(문맥) vector라고 한다.
문맥 벡터로 부터 번역을 하게된다.
시작을 하게되므로 <start> 신호를 받게된다.
<end>라는 신호를 받을때 까지 번역을 해준다.
이러한 방법을 ‘Encoder-Decoder’ 아키텍쳐라고 부르고 때로는 Sequence-to-Sequence 모델이라고 부른다.
Encoder가 하는 주 역할은 각 단어를 순차적으로 받음으로서 최종적으로 Context vector를 만드는데 있다.
Decoder의 역할은 Context vector로 부터 기계번역을 시작하는 역할,부분이다.
Potential issue is at Context vector
성공적이나 단어의 사이즈가 클때 문제가 발생한다. 문맥 벡터가 고정된 크기의 벡터이기 때문이다.
즉 문장이 길어질 경우 그리고 문맥 벡터의 크기가 충분히 크지 않은 경우 모든 정보를 함축할수 없는 문제가 있다.
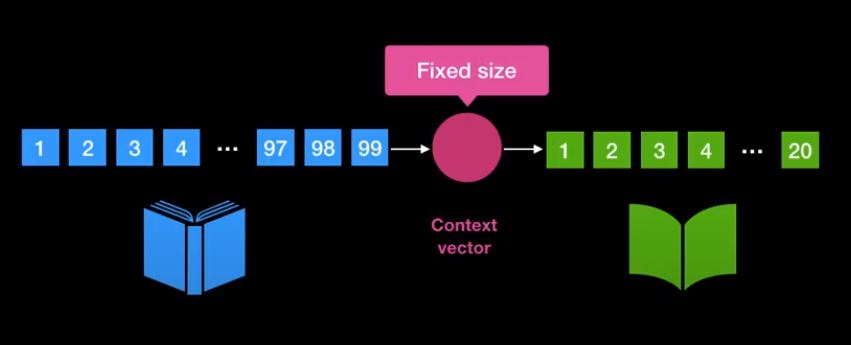
결국 문맥 벡터에 충분한 정보가 들어있지 못하기 때문에 번역에 이상이 생긴다.
How can we improve this?
고정된 Context vector를 사용하기 보다 dynamic한 Context vector를 생성하기위해 현재 상태를 갖는 encoder의 각각의 상태를 사용한다.
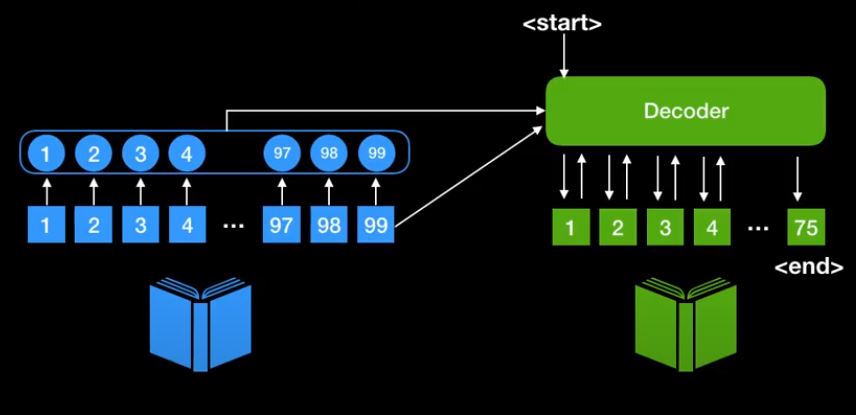
장점
- encoder 정보를 담는 벡터가 단일 context vector가 아니다.
- encoder에 있었던 모든 state중에서 뭔가 중요한 단어들에게만 집중할수 있는 매카니즘을 설계 가능하다.
Seq2Seq with Attention Mechanism
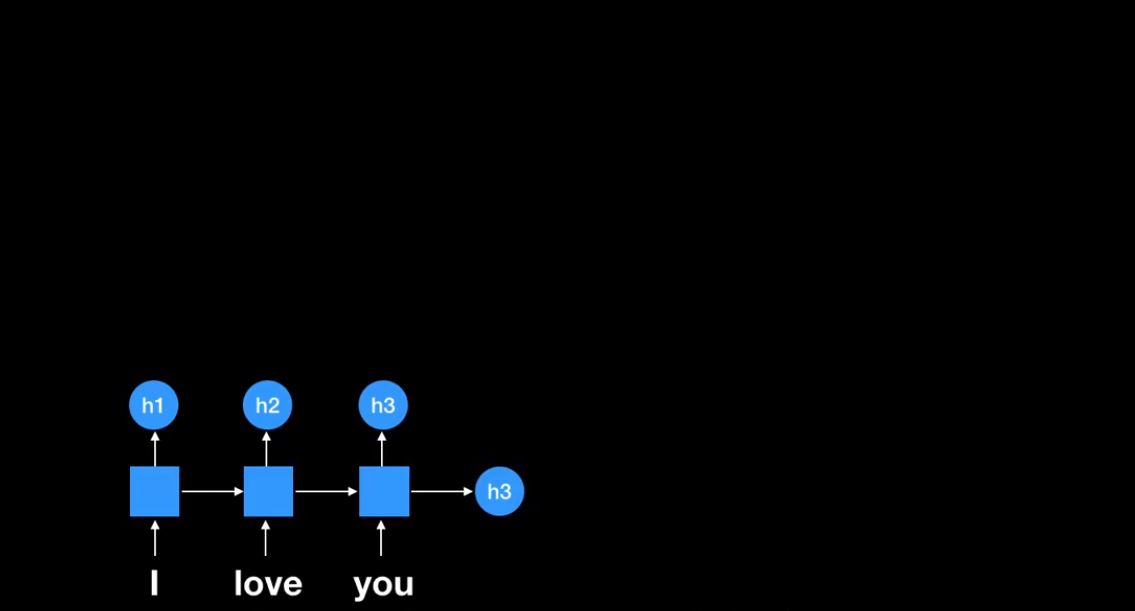
최종적으로 나온 h3는 전통적인 seq2seq 모델에서는 context vector였다.
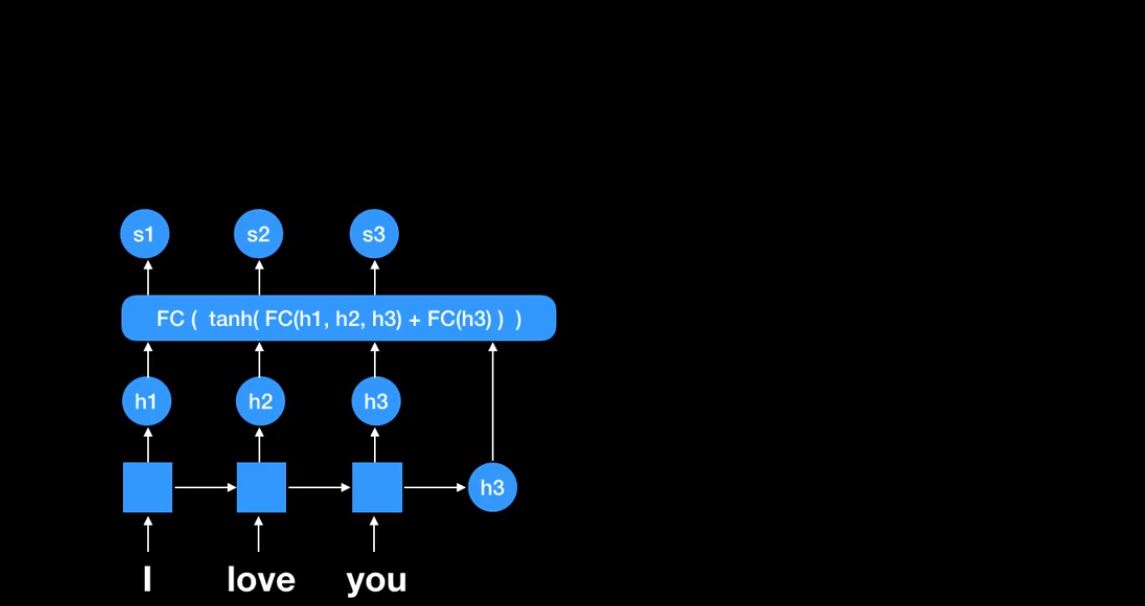
여기 Fully connect network가 있다. encoder 부분에서 나왔던 RNN cell의 states(h1,h2,h3)들을 활용한다.
초반에는 decoder에서 나오는 값이 하나도 없기 때문에 가장 마지막 h3를 마지막에 넣어준다
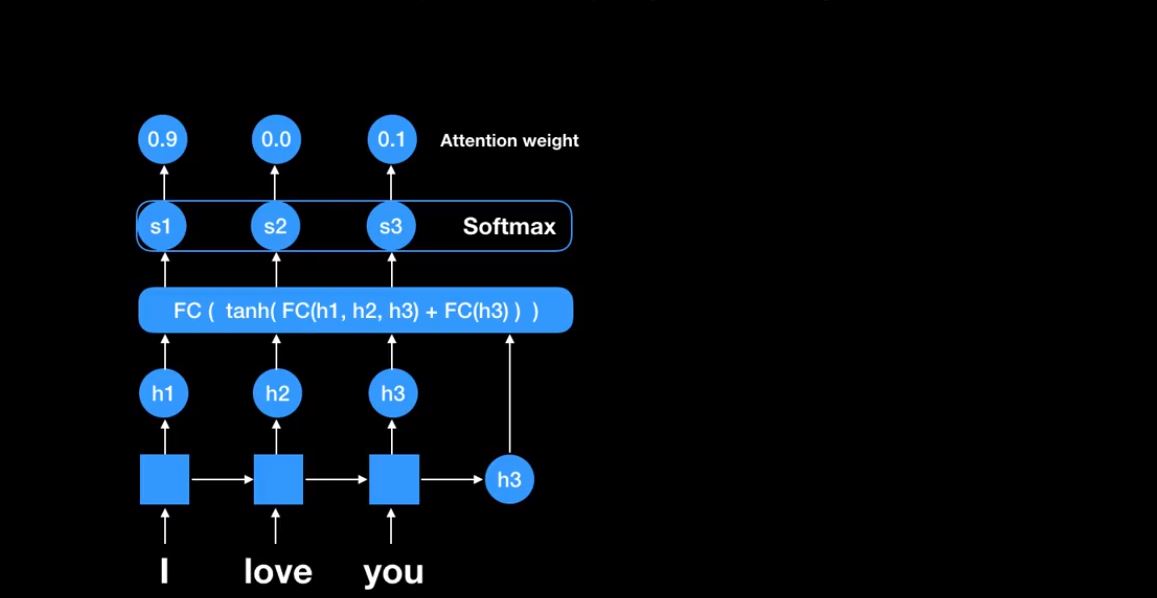
그러면 s1,s2,s3가 나온다. 이것들은 각 encoder에 있던 RNN cell의 states들의 score들이다. 이것들을 Softmax하여 확률값을 구한다. 이렇게 나온값들을 Attention weight라고 한다.
‘I’에는 90%를 집중하고 ‘love’에는 전혀 하지 않고 ‘you’에는 10%를 한다.
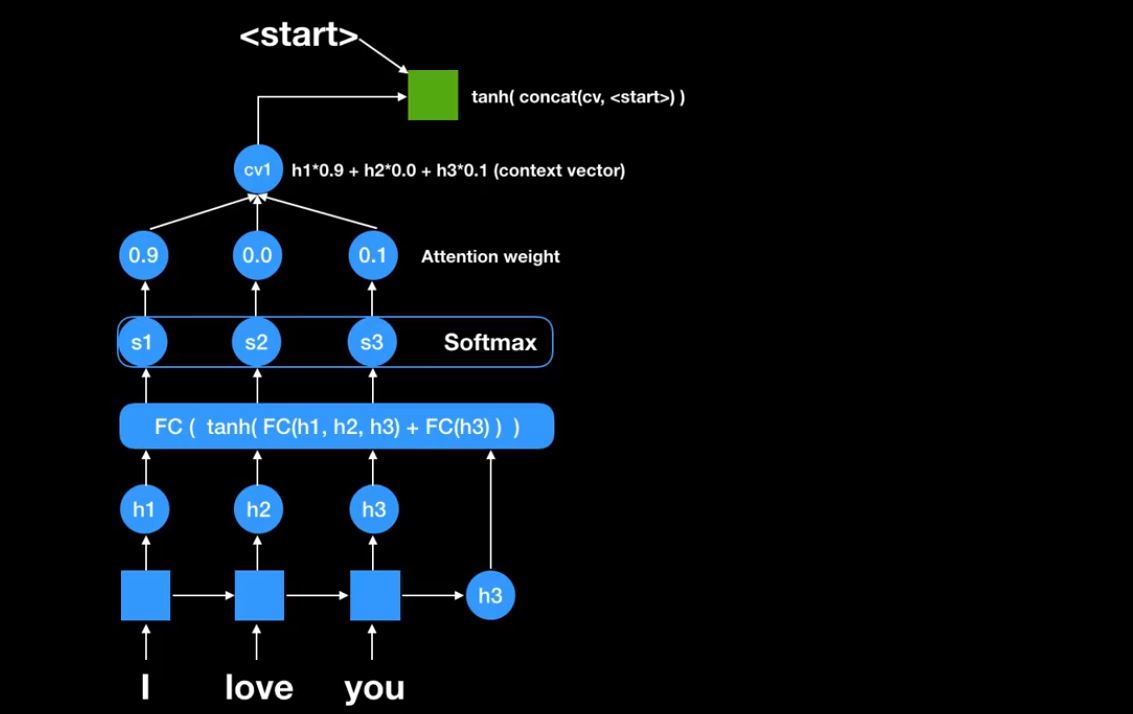
그렇게 하여 첫번째 문맥 벡터(context vector)를 만든다. cv1는 context vector를 의미한다. <start> 신호와 함께 RNN cell에 넣어준다.
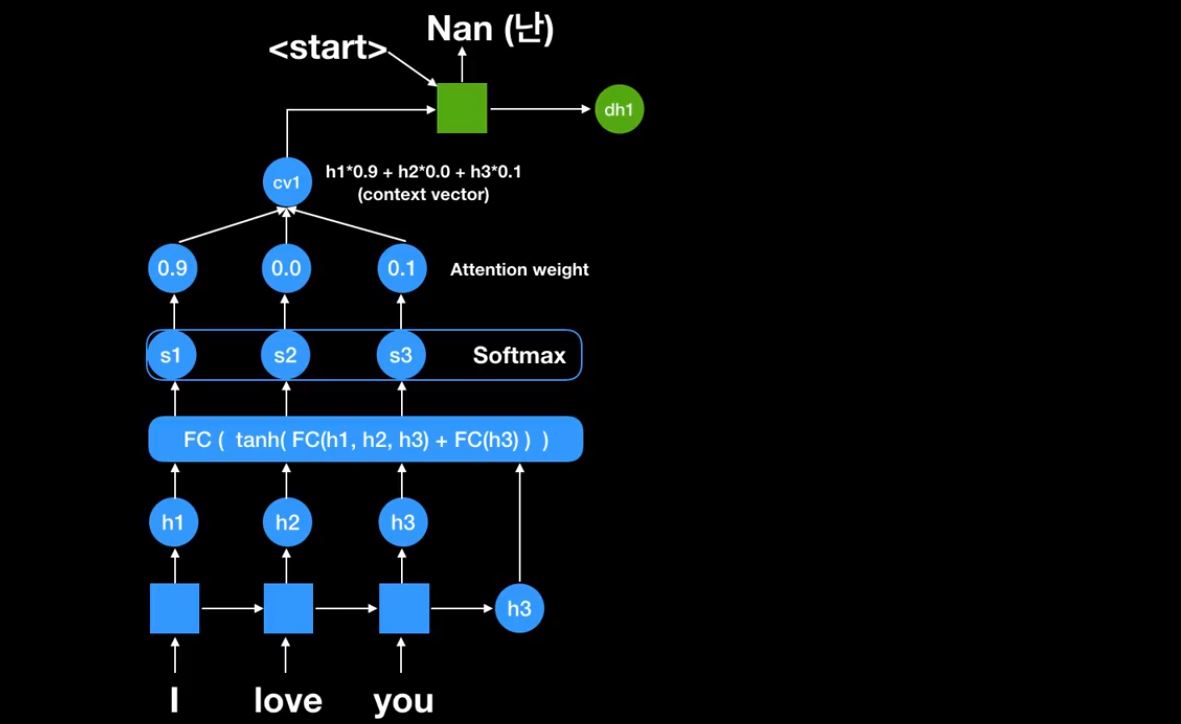
그러면 다음과 같이 첫번째 output이 나온다.
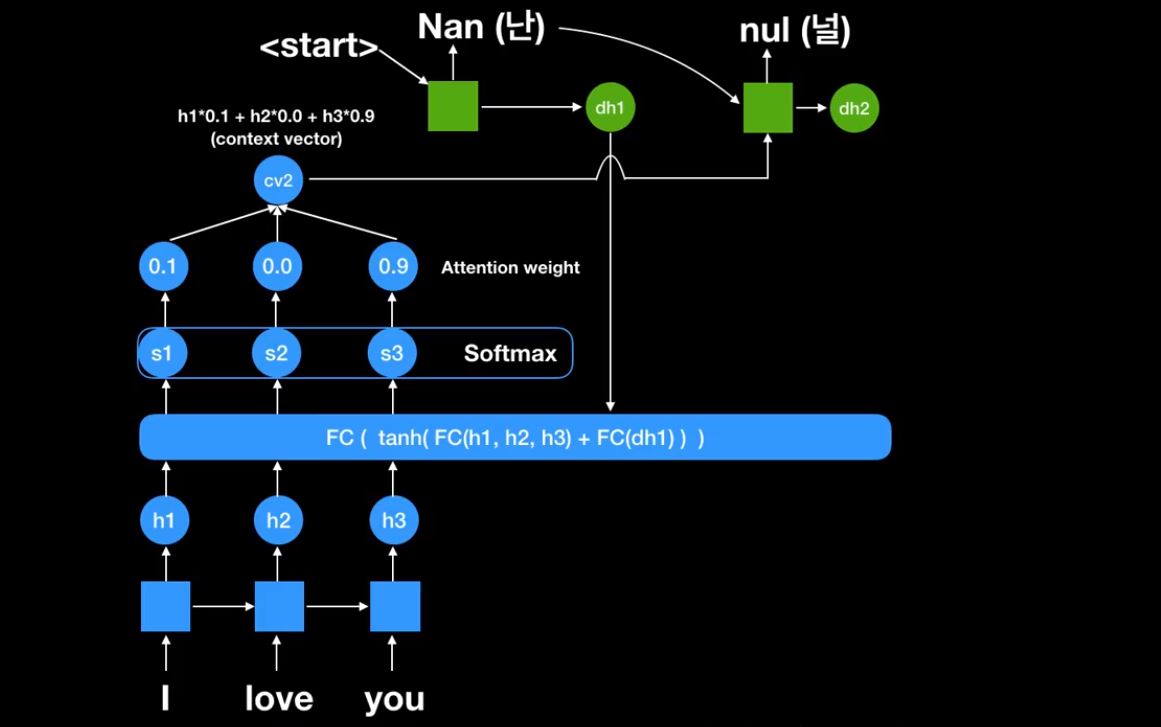
현재 decoder의 state 값을 FC network에 넣어준다.
중요한것은 s1,s2,s3가 항상 쓰인다는 것이다.
새로 만들어진 Attention weight를 가지고 새로운 cv2를 만들어 냈다. 이것을 또 RNN cell에 넣어 출력값을 얻어낸다.
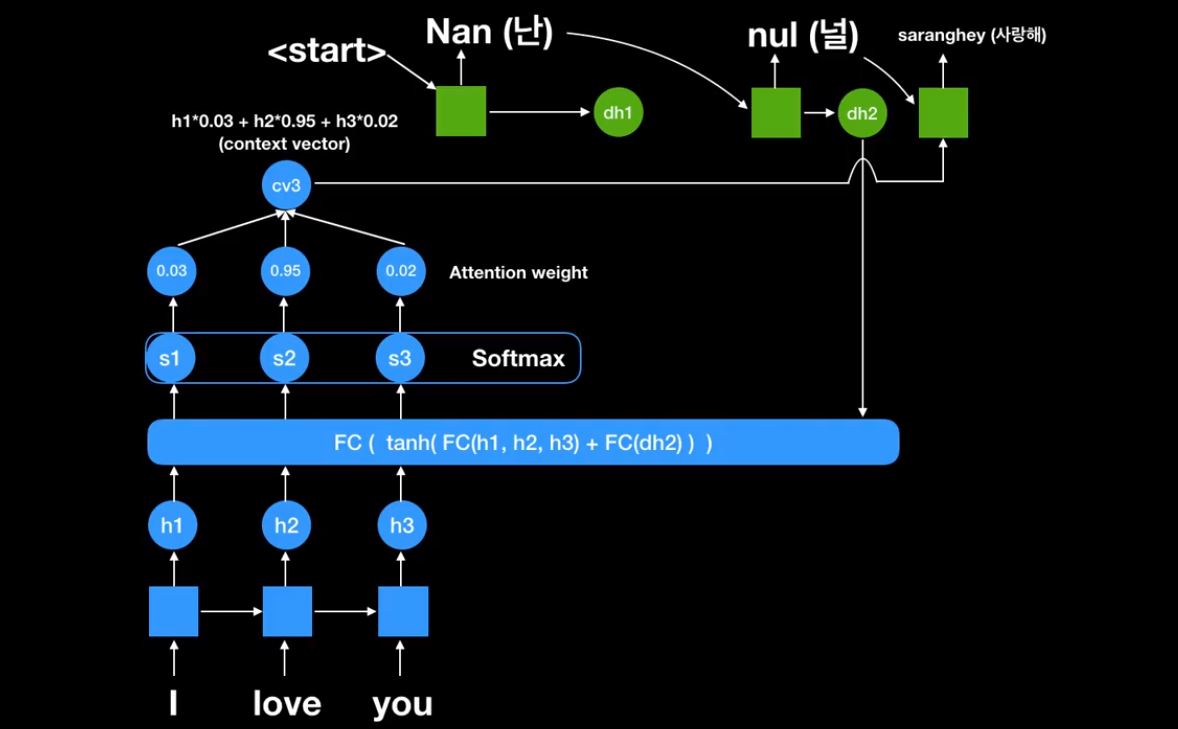
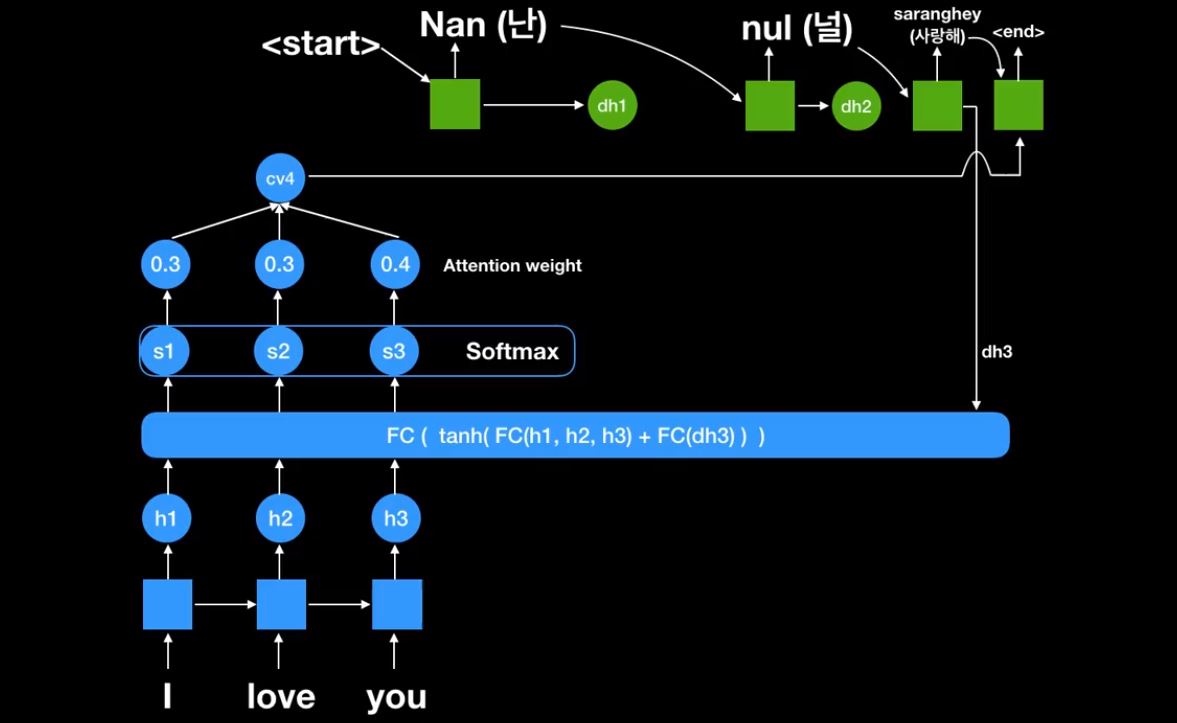
마지막 end 신호가 나올때까지 반복한다.
중요한것은
첫번째 Attention weight이다. Attention weight를 통해서 항상 encoder에서 나온 state를 가지고 어디를 집중해서 볼것인지를 본다는것이다.
두번째 context vector가 각각 state별로 decoding할때마다 달라진다는것이다.
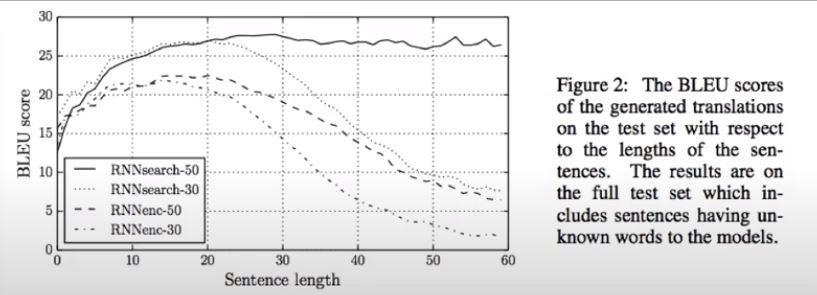
결과
seq2seq with attention vs traditional seq2seq