Frustum ConvNet
: Sliding Frustums to Aggregate Local Point-Wise Features for Amodal 3D Object Detection
arXiv 2019 Zhixin Wang • Kui Jia paper
Abstract
In this work, we propose a novel method termed Frustum ConvNet (F-ConvNet) for amodal 3D object detection from point clouds. Given 2D region proposals in an RGB image, our method first generates a sequence of frustums for each region proposal, and uses the obtained frustums to group local points.
본 연구에서는 point clouds에서 amodal 3D object detection를 위한 F-ConvNet(F-ConvNet)이라는 새로운 방법을 제안한다. RGB 이미지에서 2D region proposals을 고려할 때, 우리의 방법은 먼저 각 region proposal에 대한 equence of frustums을 생성하고, 얻은 frustums을 group local points하는데 사용한다.
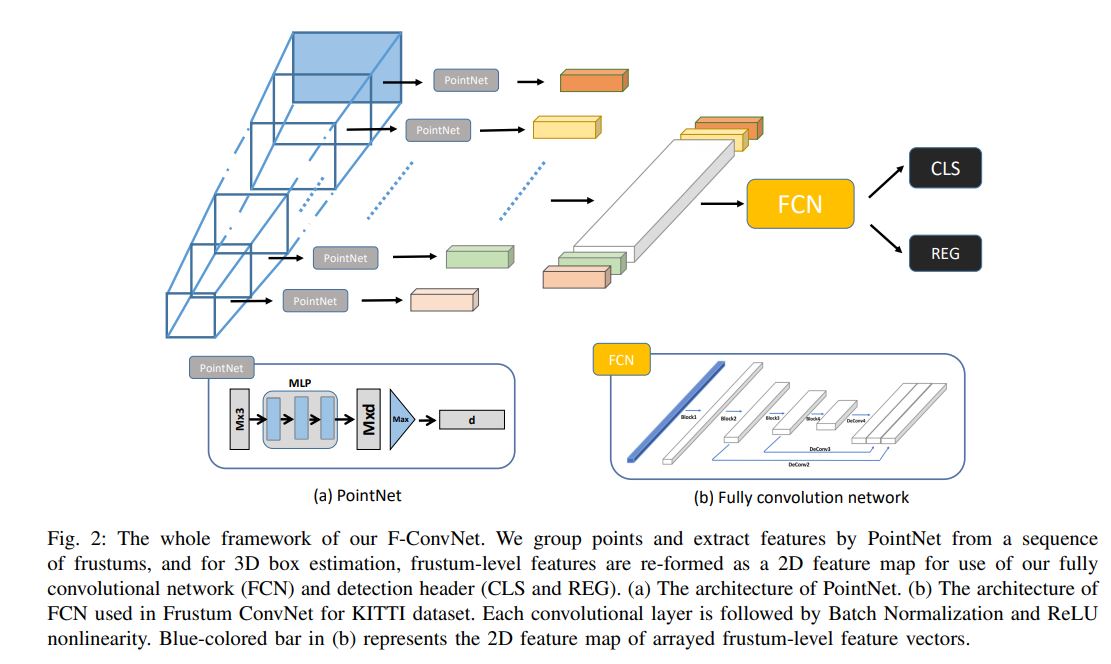
F-ConvNet aggregates point-wise features as frustum-level feature vectors, and arrays these feature vectors as a feature map for use of its subsequent component of fully convolutional network (FCN), which spatially fuses frustum-level features and supports an end-to-end and continuous estimation of oriented boxes in the 3D space.
F-ConvNet은 point-wise features을 좌frustum-level feature vectors로 집계하고, 이러한 feature vectors를 ully convolutional network (FCN)의 subsequent component를 사용하기 위한 feature map으로 배열하여 frustum-level features을 공간적으로 융합하고 3D 공간에서 oriented boxes의 end-to-end 및 continuous estimation을 지원한다.
We also propose component variants of F-ConvNet, including an FCN variant that extracts multi-resolution frustum features, and a refined use of F-ConvNet over a reduced 3D space.
Careful ablation studies verify the efficacy of these component variants.
F-ConvNet assumes no prior knowledge of the working 3D environment and is thus dataset-agnostic.
또한 multi-resolution frustum features을 추출하는 FCN variant와 축소된 3D 공간에 대한 F-ConvNet의 refined use을 포함하여 F-ConvNet의 component variants를 제안한다. Careful ablation 연구는 이러한 component variants의 효과를 검증한다. F-ConvNet은 작동 중인 3D 환경에 대한 사전 지식이 없고 데이터 세트에 구애받지 않는다.
We present experiments on both the indoor SUN-RGBD and outdoor KITTI datasets.
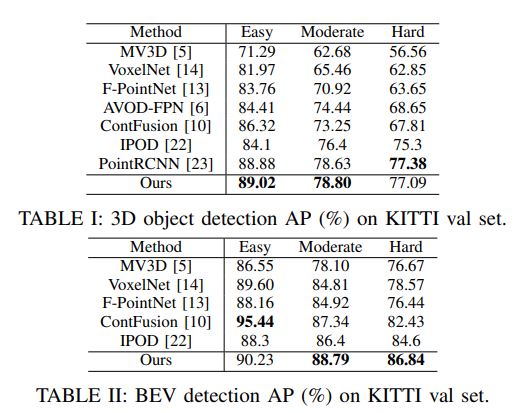
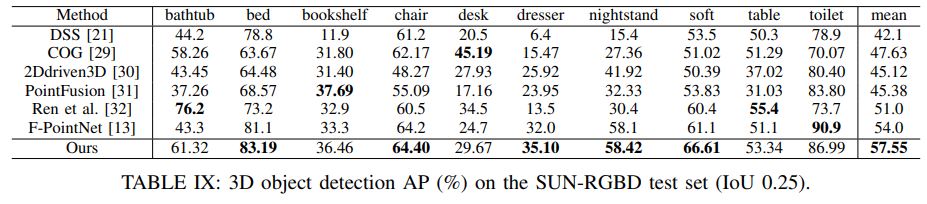
F-ConvNet outperforms all existing methods on SUN-RGBD, and at the time of submission it outperforms all published works on the KITTI benchmark.
실내 SUN-RGBD 및 실외 KITTI datasets에 대한 실험을 제시한다. F-ConvNet은 SUN-RGBD에서 모든 기존 방법을 능가하며, submission 시점에 KITTI benchmark에서 발표된 모든 작업을 능가한다.
Code has been made available at: https://github.com/zhixinwang/frustum-convnet.
1. INTRODUCTION
Detection of object instances in 3D sensory data has tremendous importance in many applications including autonomous driving, robotic object manipulation, and augmented reality.
Among others, RGB-D images and LiDAR point clouds are the most representative formats of 3D sensory data.
In practical problems, these data are usually captured by viewing objects/scenes from a single perspective; consequently, only partial surface depth of the observed objects/scenes can be captured.
The task of amodal 3D object detection is thus to estimate oriented 3D bounding boxes enclosing the full objects, given partial observations of object surface.
3D sensory 데이터에서 Detection of object instances는 자율 주행, 로봇 물체 조작 및 증강 현실을 포함한 많은 애플리케이션에서 매우 중요하다. 무엇보다도, RGB-D images과 LiDAR point clouds는 3D sensory data의 가장 대표적인 formats이다. 실제 문제에서 이러한 데이터는 일반적으로 single perspective에서 objects/scenes을 보고 캡처되므로, 관찰된 objects/scenes의 부분적인 surface depth만 캡처할 수 있다. 따라서 amodal 3D object detection은 object surface의 부분적인 관찰을 고려할 때, 전체 객체를 둘러싸는 방향의 3D bounding boxes를 추정하는 것이다.
In this work, we focus on object detection from point clouds, and assume the availability of accompanying RGB images.
이 연구에서, 우리는 point clouds로부터의 object detection에 초점을 맞추고, 동반된 RGB 이미지의 가용성을 가정한다.
Due to the discrete, unordered, and possibly sparse nature of point clouds, detecting object instances from them is challenging and requires learning techniques that are different from the established ones [1]–[3] for object detection in RGB images.
In order to leverage the expertise in 2D object detection, existing methods convert 3D point clouds either into 2D images by view projection [4]–[6], or into regular grids of voxels by quantization [7]–[10].
Although 2D object detection can be readily applied to the converted images or volumes, these methods suffer from loss of critical 3D information in the projection or quantization process.
point clouds의 이산적이고 순서가 없으며 sparse nature한 특성으로 인해 object instances를 탐지하는 것은 어렵고 RGB 이미지에서 object detection를 위해 설정된 [1]–[3]과 다른 학습 기법이 필요하다. 2D object detection에 대한 전문 지식을 활용하기 위해, 기존 방법은 뷰 투영[4]–[6]에 의한 3D point clouds를 2D images로 변환하거나 [7]–[10]에 의한 voxels의 regular grids로 변환한다. 2D 물체 감지는 변환된 이미지 또는 볼륨에 쉽게 적용될 수 있지만, 이러한 방법은 projection 또는 quantization process에서 loss of critical 3D information로 인해 어려움을 겪는다.
With the progress of point set deep learning [11], [12], recent methods [13], [14] resort to learning features directly from raw point clouds.
For example, the seminal work of F-PointNet [13] first finds local points corresponding to pixels inside a 2D region proposal, and then uses PointNet [11] to segment from these local points the foreground ones; the amodal 3D box is finally estimated from the foreground points.
Performance of this method is limited due to the reasons that (1) it is not of end-to-end learning to estimate oriented boxes, and (2) final estimation relies on too few foreground points which themselves are possibly segmented wrongly.
Methods of VoxelNet style [14]–[16] overcome both of the above limitations by partitioning 3D point cloud into a regular grid of equally spaced voxels; voxel-level features are learned and extracted, again using methods similar to PointNet [11], and are arrayed together to form feature maps that are processed subsequently by convolutional (conv) layers; amodal 3D boxes are estimated in an end-toend fashion using spatially convolved voxel-level features.
For the other side of the coin, due to unawareness of objects, sizes and positions of grid partitioning in VoxelNet [14] methods do not take object boundaries into account, and their settings usually assume prior knowledge of the 3D environment (e.g., only one object in vertical space of the KITTI dataset [17]), which, however, are not always suitable.
Motivated to address the limitations in [13], [14], we propose in this paper a novel method of amodal 3D object detection termed Frustum ConvNet (F-ConvNet).
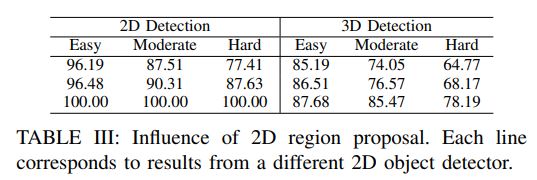
Similar to [13], our method assumes the availability of 2D region proposals in RGB images, which can be easily obtained from off-the-shelf object detectors [1]–[3], and identifies 3D points corresponding to pixels inside each region proposal.
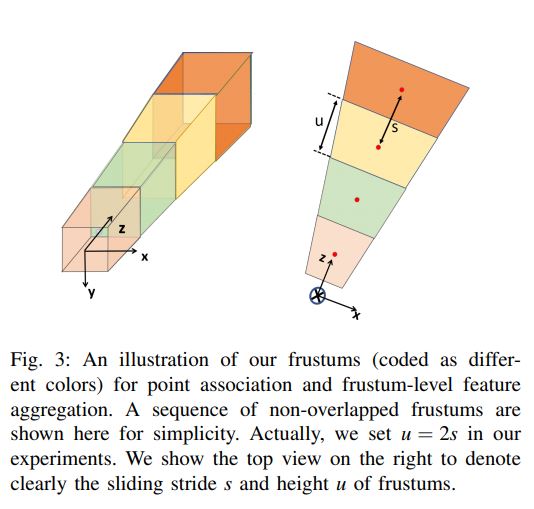
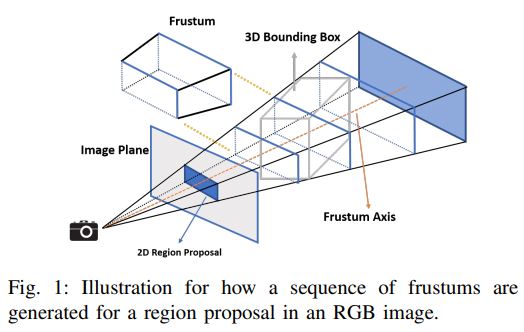
Different from [13], our method generates for each region proposal a sequence of (possibly overlapped) frustums by sliding along the frustum axis 1 (cf. Fig. 1 for an illustration).
These obtained frustums define groups of local points.
Given the sequence of frustums and point association, our F-ConvNet starts with lower, parallel layer streams of PointNet style to aggregate point-wise features as a frustum-level feature vector; it then arrays at its early stage these feature vectors of individual frustums as 2D feature maps, and uses a subsequent fully convolutional network (FCN) to down-sample and up-sample frustums such that their features are fully fused across the frustum axis at a higher frustum resolution.
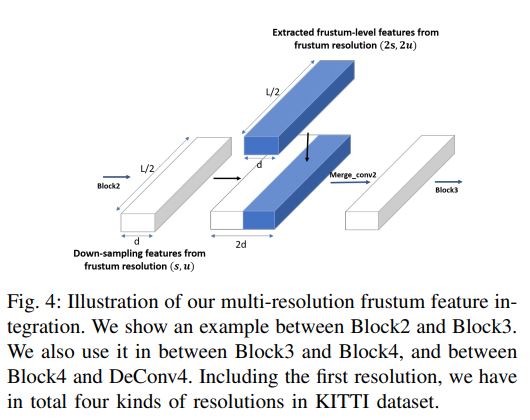
Together with a final detection header, our proposed F-ConvNet supports an end-to-end and continuous estimation of oriented 3D boxes, where we also propose an FCN variant that extracts multi-resolution frustum features.
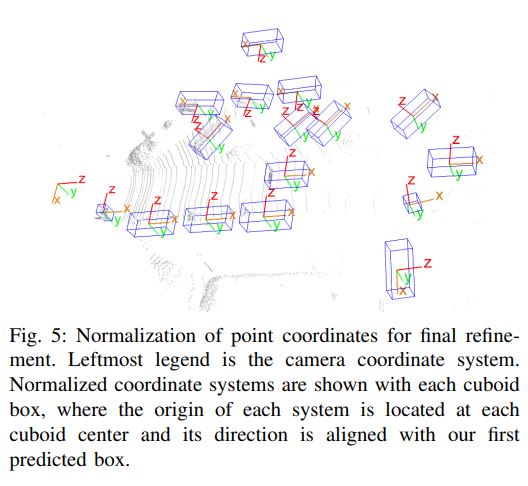
Given an initial estimation of 3D box, a final refinement using the same F-ConvNet often improves the performance further.
We present careful ablation studies that verify the efficacy of different components of F-ConvNet.
On the SUN-RGBD dataset [18], our method outperforms all existing ones.
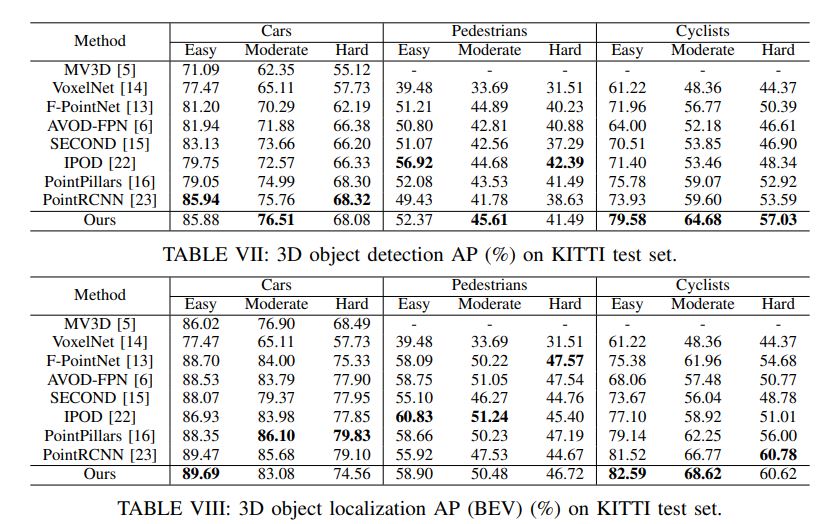
On the KITTI benchmark [17], our method outperforms all published works at the time of submission, including those working on point clouds and those working on a combination of point clouds and RGB images.
We summarize our contributions as follows.
• We propose a novel method termed Frustum ConvNet (F-ConvNet) for amodal 3D object detection from point clouds.
We use a novel grouping mechanism – sliding frustums to aggregate local point-wise features for use of a subsequent FCN.
Our proposed method supports an end-to-end estimation of oriented boxes in the 3D space that is determined by 2D region proposals.
• We propose component variants of F-ConvNet, including an FCN variant that extracts multi-resolution frustum features, and a refined use of F-ConvNet over a reduced 3D space.
Careful ablation studies verify the efficacy of these components and variants.
• F-ConvNet assumes no prior knowledge of the working 3D environment, and is thus dataset-agnostic. On the indoor SUN-RGBD dataset [18], F-ConvNet outperforms all existing methods; on the outdoor dataset of KITTI benchmark [17], it outperforms all published works at the time of submission.