Weakly-Supervised Cross-view 3D Human Pose Estimation
.
Hua, Guoliang, et al. “Weakly-supervised Cross-view 3D Human Pose Estimation.” arXiv preprint arXiv:2105.10882 (2021). paper
Abstract
Although monocular 3D human pose estimation methods have made significant progress, it’s far from being solved due to the inherent depth ambiguity.
Instead, exploiting multi-view information is a practical way to achieve absolute 3D human pose estimation.
In this paper, we propose a simple yet effective pipeline for weakly-supervised cross-view 3D human pose estimation.
By only using two camera views, our method can achieve state-of-the-art performance in a weakly-supervised manner, requiring no 3D ground truth but only 2D annotations.
Specifically, our method contains two steps: triangulation and refinement.
First, given the 2D keypoints that can be obtained through any classic 2D detection methods, triangulation is performed across two views to lift the 2D keypoints into coarse 3D poses.
Then, a novel cross-view U-shaped graph convolutional network (CV-UGCN), which can explore the spatial configurations and cross-view correlations, is designed to refine the coarse 3D poses.
In particular, the refinement progress is achieved through weakly-supervised learning, in which geometric and structure-aware consistency checks are performed.
We evaluate our method on the standard benchmark dataset, Human3.6M. The Mean Per Joint Position Error on the benchmark dataset is 27.4 mm, which outperforms the state-of-the-arts remarkably (27.4 mm vs 30.2 mm).
1 Introduction
3D human pose estimation aims to produce a 3-dimensional figure that describes the spatial position of the depicted person. This task has drawn tremendous attention in the past decades [Li and Chan, 2014; Chen and Ramanan, 2017; Zhou et al., 2017], playing a significant role in many applications such as action recognition, virtual and augmented reality, human-robot interaction, etc. Many recent works [Martinez et al., 2017; Xu et al., 2020; Fabbri et al., 2020] focus on estimating 3D human poses from monocular inputs, either images or 2D keypoints. However, it is ill-posed due to the inherent depth ambiguity, since multiple 3D poses can map to the same 2D keypoints. As a result, most monocular methods only estimate the relative positions to the root joint and fail to estimate the absolute 3D poses, which greatly limits practical applications. Instead, exploiting multi-view information is arguably the best way to achieve absolute 3D pose estimation [Pavlakos et al., 2017b].
Multi-view human pose estimation methods benefit from the complementary information from different camera views, e.g. multi-view geometric constraints to resolve the depth ambiguity, different views of the depicted person to deal with the occlusion problem.
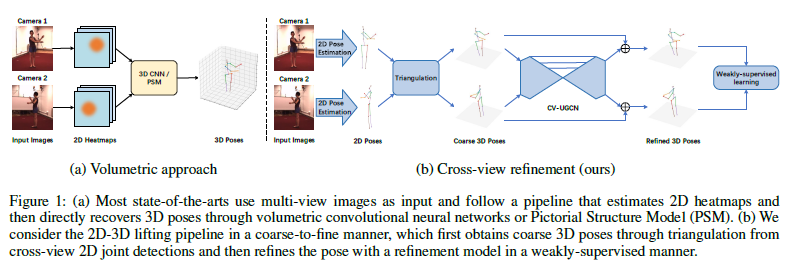
Many existing multi-view based methods [Iskakov et al., 2019; Qiu et al., 2019; Kocabas et al., 2019] follow a pipeline that first takes multi-view images as input to predict 2D detection heatmaps and then projects them to 3D poses through volumetric convolutional networks or Pictorial Structure Model (PSM) [Pavlakos et al., 2017b; Chen and Yuille, 2014], as shown in Figure 1(a).
However, using the convolutional neural network to perform 2D-3D lifting requires quantities of labeled 3D data as supervision, which is difficult and costly to collect.
PSM discretizes the space around the root joint by an \(N \times N \times N\) grid and assigns each joint to one of the \(N^3\) bins (hypotheses), therefore requiring no 3D ground truth.
However, the 2D-3D lifting accuracy of PSM based method is subject to the number of grids, and the computation complexity is of the order of \(O(N^6)\) which is computationally expensive.
To release the requirement of large quantities of 3D ground truth and take the computation complexity into consideration, a simple yet effective pipeline (see Figure 1(b)) is proposed in this paper for cross-view 3D human pose estimation.
Different from other methods, our method estimates 3D human poses from coarse to fine and contains two steps: triangulation and refinement. Considering the increasing number of camera views will bring more computation and reduce the flexibility of application in the wild, we only use two camera views for training and inference.
In the first step, we perform the triangulation between two camera views to lift 2D poses that can be obtained through any classic 2D keypoint detection methods to the 3D space. However, the triangulated 3D poses are noisy and unreliable due to the errors of 2D keypoint detection and camera parameters calibration, thus requiring further refinement.
In the refinement progress, a lightweight cross-view Ushaped graph convolutional network (CV-UGCN) is designed to refine the coarse 3D poses. As far as we know, it’s the first time that GCN is utilized to integrate cross-view information for 3D human pose estimation. By taking the cross-view coarse 3D poses as input, CV-UGCN is able to exploit spatial configurations and cross-view correlations to refine the poses to be more rational. Meanwhile, CV-UGCN is trained in a weakly-supervised manner, requiring no 3D ground truth but only 2D annotations. Specifically, by making full use of the cross-view geometric constraints, geometric and structureaware consistency checks are introduced as the learning objective to train the network end-to-end.
We summarize our contributions as follows:
A simple yet effective pipeline is proposed for crossview 3D human pose estimation, which estimates the 3D human poses from coarse to fine by using the triangulation and the refinement model.
A cross-view U-shaped graph convolutional network (CV-UGCN), which can take advantage of spatial configurations and cross-view correlations, is proposed as the refinement model.
A weakly-supervised learning objective containing geometric and structure-aware consistency checks is introduced, therefore releasing from the requirement of large quantities of 3D ground truth for training.
Extensive experiments have been conducted on the benchmark dataset, Human3.6M, to verify the effectiveness of our method. The Mean Per Joint Position Error (MPJPE) on the benchmark dataset is 27.4 mm, which outperforms the stateof- the-arts remarkably (27.4 mm vs 30.2 mm).
2 Related Work
Single-view 3D pose estimation.
Current promising solutions for monocular 3D pose estimation can be divided into two categories. Methods of the first category directly regress the 3D poses from monocular images. [Pavlakos et al., 2017a] introduced a volumetric representation for 3D human poses, while required a sophisticating deep network architecture that is impractical in application. In the second category, these works first estimate 2D keypoints and then lift 2D poses to the 3D space (2D-3D lifting). [Martinez et al., 2017] predicted 3D poses via an effective fully-connected residual network and showed low error rates when using 2D ground truth as input. [Cai et al., 2019] presented a local-to-global GCN to exploit spatial-temporal relationships to estimate 3D poses from a sequence of skeletons. Meanwhile, they introduced a pose refinement step to further improve the estimation accuracy. However, they only utilized the 2D detections to constrain the depth-normalized poses, while ignored the refinement for depth values. Different from [Cai et al., 2019], we perform both 3D transformation and 2D reprojection consistency checks in our refinement model, so that the refinement is more sufficient.
Multi-view 3D pose estimation.
In order to estimate the absolute 3D poses, recent works seek to utilize information from multiple synchronized cameras to solve the problem of depth ambiguity. Most multi-view based approaches use 3D volumes to aggregate 2D heatmap predictions. [Qiu et al., 2019] presented a cross-view fusion scheme to jointly estimate 2D heatmaps of multiple views and then used a recursive Pictorial Structure Model to estimate the absolute 3D poses. [Iskakov et al., 2019] proposed a learnable triangulation method to regress 3D poses from multiple views. However, volumetric approaches are computationally demanding. To recover 3D poses from multi-view images without using compute-intensive volumetric grids, [Remelli et al., 2020] exploited 3D geometry to fuse input images into a unified latent representation of poses. Different from these methods that embedded the improved 2D detector into their model to obtain more accurate 2D poses to further improve the 3D pose estimation, our method focuses on the task of 2D-3D lifting and can be easily integrated with any 2D detectors to achieve 3D pose estimation with a lightweight refinement model.
Weakly/self-supervised methods. Because 3D human pose datasets are limited and collecting 3D human pose annotations is costly, researchers have resorted to weakly or self-supervised approaches. [Zhou et al., 2017] proposed a weakly-supervised transfer learning method, which is effective in the absence of depth labels. To tackle the overfitting problem, [Wandt and Rosenhahn, 2019] proposed a weaklysupervised reprojection network (RepNet) by using an adversarial training approach, which generalized well to unknown data. Moreover, in [Kundu et al., 2020], a self-supervised learning method was proposed to estimate 3D poses from unlabeled video frames that disentangled the inherent factors of variations via part guided human image synthesis. Compared with previous methods, our method has the advantage of decomposing the challenging 3D human pose estimation task into two steps and making full use of geometric and structureaware consistency checks for weakly-supervised learning.