Self-Supervised Multi-View Synchronization Learning for 3D Pose Estimation
.
Jenni, Simon, and Paolo Favaro. “Self-Supervised Multi-View Synchronization Learning for 3D Pose Estimation.” Proceedings of the Asian Conference on Computer Vision. 2020. paper
- Abstract
- 1. Introduction
- 2 Prior work
- 3 Unsupervised learning of 3D pose-discriminative features
- 4 Experiments
- 5 Conclusions
Abstract
Current state-of-the-art methods cast monocular 3D human pose estimation as a learning problem by training neural networks on large data sets of images and corresponding skeleton poses.
In contrast, we propose an approach that can exploit small annotated data sets by fine-tuning networks pre-trained via self-supervised learning on (large) unlabeled data sets.
To drive such networks towards supporting 3D pose estimation during the pre-training step, we introduce a novel self-supervised feature learning task designed to focus on the 3D structure in an image.
현재의 state-of-the-art methods은 large data images sets와 해당 skeleton poses에 neural networks를 훈련시켜 monocular 3D human pose estimation을 학습 문제로 캐스팅한다.
대조적으로, 우리는 (large) unlabeled data sets에 대한 self-supervised learning을 통해 pre-trained된 networks를 fine-tuning하여 small annotated data sets를 활용할 수 있는 approach를 제안한다.
이러한 networks를 pre-training step에서 3D pose estimation을 지원하는 방향으로 유도하기 위해, 우리는 image의 3D structure에 중점을 두도록 설계된 novel self-supervised feature learning task를 소개한다.
We exploit images extracted from videos captured with a multi-view camera system.
The task is to classify whether two images depict two views of the same scene up to a rigid transformation.
In a multi-view data set, where objects deform in a non-rigid manner, a rigid transformation occurs only between two views taken at the exact same time, i.e., when they are synchronized.
We demonstrate the effectiveness of the synchronization task on the Human3.6M data set and achieve state-of-the-art results in 3D human pose estimation.
multi-view camera system으로 캡처한 비디오에서 추출한 이미지를 활용한다.
과제는 두 개의 영상이 동일한 장면의 두 views를 rigid transformation까지 묘사하는지 여부를 분류하는 것이다.
객체가 non-rigid 방식으로 변형되는 multi-view data set에서, rigid transformation은 정확히 동시에 수행된 두 views 사이에서 발생한다, 즉 객체가 동기화될 때에만 발생한다.
우리는 Human3.6M data set에서 synchronization task의 effectiveness를 보여주고 3D human pose estimation에서 state-of-the-art results를 성취한다.
1. Introduction
The ability to accurately reconstruct the 3D human pose from a single real image opens a wide variety of applications including computer graphics animation, postural analysis and rehabilitation, human-computer interaction, and image understanding [1].
State-of-the-art methods for monocular 3D human pose estimation employ neural networks and require large training data sets, where each sample is a pair consisting of an image and its corresponding 3D pose annotation [2].
The collection of such data sets is expensive, time-consuming, and, because it requires controlled lab settings, the diversity of motions, viewpoints, subjects, appearance and illumination, is limited (see Fig. 1).
Ideally, to maximize diversity, data should be collected in the wild.
However, in this case precise 3D annotation is difficult to obtain and might require costly human intervention.
single real image에서 3D human pose를 정확하게 reconstruct할 수 있는 기능은 computer graphics animation, postural analysis 및 재활, 인간과 컴퓨터 상호 작용, 이미지 이해 등 다양한 애플리케이션을 개방한다[1]. monocular 3D human pose estimation을 위한 State-of-the-art methods은 neural networks를 사용하며 각 sample이 image와 해당 3D pose annotation으로 구성된 pair인 large training data sets를 필요로 한다[2]. 이러한 데이터 세트의 수집은 비용이 많이 들고 시간이 많이 소요되며, 통제된 실험실 설정이 필요하기 때문에 움직임, 관점, 피사체, 외관 및 조명의 다양성이 제한된다(Fig. 1 참조). 이상적으로는 다양성을 최대화하기 위해 데이터를 in the wild에서 수집해야 한다. 그러나 이 경우 정밀한 3D annotation이 어려우며 비용이 많이 드는 인간의 개입이 필요할 수 있다.
In this paper, we overcome the above limitations via self-supervised learning (SSL).
SSL is a method to build powerful latent representations by training a neural network to solve a so-called pretext task in a supervised manner, but without manual annotation [3].
The pretext task is typically an artificial problem, where a model is asked to output the transformation that was applied to the data.
One way to exploit models trained with SSL is to transfer them to some target task on a small labeled data set via fine-tuning [3].
The performance of the transferred representations depends on how related the pretext task is to the target task.
Thus, to build latent representations relevant to 3D human poses, we propose a pretext task that implicitly learns 3D structures.
To collect data suitable to this goal, examples from nature point towards multi-view imaging systems.
본 논문에서는 self-supervised learning (SSL)을 통해 위의 한계를 극복한다.
SSL은 manual annotation 없이 supervised 방식에서 so-called pretext task를 해결하기 위해 neural network을 훈련시켜 강력한 latent representations을 구축하는 방법이다[3].
pretext task은 일반적으로 artificial problem으로, 모델이 데이터에 적용된 변환을 출력하도록 요청된다.
SSL로 훈련된 모델을 활용하는 한 가지 방법은 fine-tuning을 통해 small labeled data set의 일부 target task으로 모델을 transfer하는 것이다[3].
transferred된 representations의 성능은 pretext task가 target task와 얼마나 관련이 있는지에 따라 달라진다.
따라서, 3D human poses와 관련된 latent representations을 구축하기 위해, 우리는 3D structures를 암묵적으로 학습하는 pretext task을 제안한다.
이 목표에 적합한 data를 수집하기 위해 자연에서 multi-view imaging systems을 가리키는 예가 나와 있다.
In fact, the visual system in many animal species hinges on the presence of two or multiple eyes to achieve a 3D perception of the world [4, 5].
3D perception is often exemplified by considering two views of the same scene captured at the same time and by studying the correspondence problem.
Thus, we take inspiration from this setting and pose the task of determining if two images have been captured at exactly the same time.
In general, the main difference between two views captured at the same time and when they are not, is that the former are always related by a rigid transformation and the latter is potentially not (e.g., in the presence of articulated or deformable motion, or multiple rigid motions).
Therefore, we propose as pretext task the detection of synchronized views, which translates into a classification of rigid versus non-rigid motion.
사실, 많은 동물 종들의 시각 시스템은 세계에 대한 3D 인식을 달성하기 위해 두 개 또는 여러 개의 눈의 존재에 달려 있다 [4, 5].
3D 인식은 종종 동시에 포착된 동일한 장면의 두 views를 고려하고 대응 문제를 연구함으로써 예시된다.
따라서, 우리는 이 설정에서 영감을 얻어 두 개의 이미지가 정확히 동시에 캡처되었는지 여부를 결정하는 작업을 제기한다.
일반적으로, 동시에 포착된 두 views와 그렇지 않을 때의 주요 차이점은 전자는 항상 rigid transformation에 의해 관련되며 후자는 잠재적으로 그렇지 않다는 것이다(예: 관절 또는 변형 가능한 motion또는 multiple rigid motions).
따라서, 우리는 synchronized views의 detection을 pretext task으로 제안하며, 이는 rigid와 non-rigid motion의 분류로 해석된다.
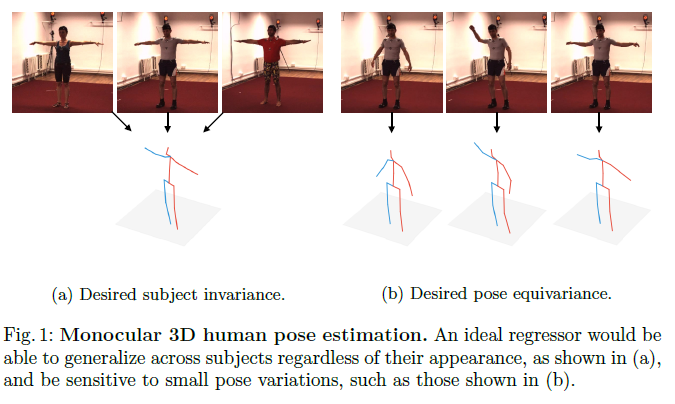
As shown in Fig. 1, we aim to learn a latent representation that can generalize across subjects and that is sensitive to small pose variations.
Thus, we train our model with pairs of images, where the subject identity is irrelevant to the pretext task and where the difference between the task categories are small pose variations.
Fig. 1에서와 같이, 우리는 subjects에 걸쳐 일반화할 수 있고 작은 pose 변화에 민감한 latent representation을 배우는 것을 목표로 한다.
따라서, 우리는 subject identity가 pretext task과 무관하고 task categories 간의 차이가 작은 pose 변형인 이미지 쌍으로 우리의 모델을 훈련시킨다.
To do so, we use two views of the same subject as the synchronized (i.e., rigid motion) pair and two views taken at different (but not too distant) time instants as the unsynchronized (i.e., non-rigid motion) pair.1
Since these pairs share the same subject (as well as the appearance) in all images, the model cannot use this as a cue to learn the correct classification.
Moreover, we believe that the weight decay term that we add to the loss may also help to reduce the effect of parameters that are subject-dependent, since there are no other incentives from the loss to preserve them.
이를 위해 synchronized(즉, rigid motion) pair로 동일한 subject의 두 개의 views와 unsynchronized(즉, non-rigid motion) pair로로 서로 다른(너무 멀지는 않은) time instants에서 취한 두 개의 views를 사용한다.
이 pairs들은 모든 이미지에서 동일한 subject(외관뿐 아니라)를 공유하기 때문에 모델은 correct classification를 학습하는 cue로 사용할 수 없다.
또한, 우리는 loss에 추가하는 weight decay term이 그것들을 보존하기 위한 loss로 인한 다른 incentives가 없기 때문에, subject-dependent한 parameters의 영향을 줄이는 데 도움이 될 수 있다고 믿는다.
Because the pair of unsynchronized images is close in time, the deformation is rather small and forces the model to learn to discriminate small pose variations.
Furthermore, to make the representation sensitive to left-right symmetries of the human pose, we also introduce in the pretext task as a second goal the classification of two synchronized views into horizontally flipped or not.
This formulation of the SSL task allows to potentially train a neural network on data captured in the wild simply by using a synchronized multi-camera system.
As we show in our experiments, the learned representation successfully embeds 3D human poses and it further improves if the background can also be removed from the images.
We train and evaluate our SSL pre-training on the Human3.6M data set [2], and find that it yields state-of-the-art results when compared to other methods under the same training conditions.
unsynchronized images의 pair가 time에 가까우므로 deformation은 다소 작고 model이 small pose variations를 구별하는 방법을 배우도록 강요한다.
또한, representation을 human pose의 left-right symmetries에 민감하게 만들기 위해, 우리는 두 번째 목표로서 두 개의 synchronized views를 수평 플립 또는 안됨으로 분류하는 것을 pretext task에서 소개한다.
이 SSL task의 formulation은 synchronized multi-camera system을 사용하는 것만으로 in the wild에서 캡처된 데이터에 대한 neural network를 잠재적으로 훈련시킬 수 있다.
우리의 실험에서 보여주듯이, 학습된 representation은 성공적으로 3D human poses를 embeds하고, background도 images에서 제거할 수 있다면 더욱 개선된다.
우리는 Human3.6M data set [2]에 대한 SSL pre-training을 훈련하고 평가한다 그리고 통해 동일한 훈련 조건에서 다른 방법과 비교했을 때 state-of-the-art results를 얻을 수 있다.
We show quantitatively and qualitatively that our trained model can generalize across subjects and is sensitive to small pose variations.
Finally, we believe that this approach can also be easily incorporated in other methods to exploit additional available labeling (e.g., 2D poses). Code will be made available on our project page https://sjenni.github.io/multiview-sync-ssl.
Our contributions are:
1) A novel self-supervised learning task for multi-view data to recognize when two views are synchronized and/or flipped;
2) Extensive ablation experiments to demonstrate the importance of avoiding shortcuts via the static background removal and the effect of different feature fusion strategies;
3) State-of-the-art performance on 3D human pose estimation benchmarks.
2 Prior work
In this section, we briefly review literature in self-supervised learning, human pose estimation, representation learning and synchronization, that is relevant to our approach.
Self-supervised learning.
Self-supervised learning is a type of unsupervised representation learning that has demonstrated impressive performance on image and video benchmarks.
These methods exploit pretext tasks that require no human annotation, i.e., the labels can be generated automatically.
Some methods are based on predicting part of the data [6–8], some are based on contrastive learning or clustering [9–11], others are based on recognizing absolute or relative transformations [12–14].
Our task is most closely related to the last category since we aim to recognize a transformation in time between two views.
Unsupervised learning of 3D.
Recent progress in unsupervised learning has shown promising results for learning implicit and explicit generative 3D models from natural images [15–17].
The focus in these methods is on modelling 3D and not performance on downstream tasks.
Our goal is to learn general purpose 3D features that perform well on downstream tasks such as 3D pose estimation.
Synchronization. Learning the alignment of multiple frames taken from different views is an important component of many vision systems.
Classical approaches are based on fitting local descriptors [18–20].
More recently, methods based on metric learning [21] or that exploit audio [22] have been proposed.
We provide a simple learning based approach by posing the synchronization problem as a binary classification task.
Our aim is not to achieve synchronization for its own sake, but to learn a useful image representation as a byproduct.
Monocular 3D pose estimation.
State-of-the-art 3D pose estimation methods make use of large annotated in-the-wild 2D pose data sets [23] and data sets with ground truth 3D pose obtained in indoor lab environments.
We identify two main categories of methods:
1) Methods that learn the mapping to 3D pose directly from images [24–32] often trained jointly with 2D poses [33–37], and
2) Methods that learn the mapping of images to 3D poses from predicted or ground truth 2D poses [38–46].
To deal with the limited amount of 3D annotations, some methods explored the use of synthetic training data [47–49].
In our transfer learning experiments, we follow the first category and predict 3D poses directly from images.
However, we do not use any 2D annotations.
Weakly supervised methods.
Much prior work has focused on reducing the need for 3D annotations.
One approach is weak supervision, where only 2D annotation is used. These methods are typically based on minimizing the re-projection error of a predicted 3D pose [50–56].
To resolve ambiguities and constrain the 3D, some methods require multi-view data [50–52], while others rely on unpaired 3D data used via adversarial training [54, 55].
[53] solely relies on 2D annotation and uses an adversarial loss on random projections of the 3D pose.
Our aim is not to rely on a weaker form of supervision (i.e., 2D annotations) and instead leverage multi-view data to learn a representation that can be transferred on a few annotated examples to the 3D estimation tasks with a good performance.
Self-supervised methods for 3D human pose estimation. Here we consider methods that do not make use of any additional supervision, e.g., in the form of 2D pose annotation.
These are methods that learn representations on unlabelled data and can be transferred via fine-tuning using a limited amount of 3D annotation. Rhodin et al. [57] learn a 3D representation via novel view synthesis, i.e., by reconstructing one view from another.
Their method relies on synchronized multi-view data, knowledge of camera extrinsics and background images.
Mitra et al. [58] use metric learning on multi-view data.
The distance in feature space for images with the same pose, but different viewpoint is minimized while the distance to hard negatives sampled from the mini-batch is maximized.
By construction, the resulting representation is view invariant (the local camera coordinate system is lost) and the transfer can only be performed in a canonical, rotation-invariant coordinate system.
We also exploit multi-view data in our pre-training task. In contrast to [57], our task does not rely on knowledge of camera parameters and unlike [58] we successfully transfer our features to pose prediction in the local camera system.
3 Unsupervised learning of 3D pose-discriminative features
3.1 Classifying synchronized and flipped views
Synchronized pairs.
Unsynchronized pairs.
Flipped pairs.
3.2 Static backgrounds introduce shortcuts
3.3 Implementation
3.4 Transfer to 3D human pose estimation
4 Experiments
Dataset.
Metrics.
4.1 Ablations
(a)-(d) Influence of background removal:
(e)-(f) Combination of self-supervision signals:
(h)-(k) Fusion of features:
(l)-(m) Necessity of multi-view data:
4.2 Comparison to prior work
4.3 Evaluation of the synchronization task
Generalization across subjects.
Synchronization performance on test subjects.
5 Conclusions
We propose a novel self-supervised learning method to tackle monocular 3D human pose estimation. Our method delivers a high performance without requiring large manually labeled data sets (e.g., with 2D or 3D poses). To avoid such detailed annotation, we exploit a novel self-supervised task that leads to a representation that supports 3D pose estimation. Our task is to detect when two views have been captured at the same time (and thus the scene is related by a rigid transformation) and when they are horizontally flipped with respect to one another. We show on the well-known Human3.6M data set that these two objectives build features that generalize across subjects and are highly sensitive to small pose variations.
우리는 monocular 3D human pose estimation을 다루기 위한 novel self-supervised learning method을 제안한다. 우리의 방법은 large manually labeled data sets(예: 2D 또는 3D poses)를 요구하지 않고 높은 성능을 제공한다. 이러한 detailed annotation을 피하기 위해, 우리는 3D pose estimation을 지원하는 representation으로 이어지는 novel self-supervised task을 활용한다. 우리의 작업은 두 개의 views가 동시에 캡처되었을 때와(따라서 장면이 rigid transformation에 의해 관련됨) 서로에 대해 수평으로 플립되었을 때를 detect하는 것이다.