Anomaly Detection(이상 탐지)
(paper)[https://arxiv.org/abs/1805.10917] (my_code)[https://github.com/khw11044/My_GOAD]
Abstract
1학기가 끝났다.
1학기 수업중에 딥러닝 응용 및 실습 수업을 들었다.
Openset recognition에 대해 알게 되었다.
closed set, open set, traditional classification, one-class classification, one shot, few shot, zero shot등을 알게되었다.
out-of-distribution, outlier detection, anomaly detection, novelty detection등에 대해 알게되었다.
논문 5개를 3주만에 읽고 중간 발표를 했다. 기말 발표는 이쪽분야의 개인 프로젝트를 하는것이였다.
anomaly detection에 다양한 methods들이 있다. 그중에 가장 대표적인것은 reconstruction-based methods, probabilistic methods(distribution methods), classification-based methods 가 있다.
나는 이중에서 classification-based method인 CLASSIFICATION-BASED ANOMALY DETECTION FOR GENERAL DATA 논문 기반으로 benchmark dataset이 아닌 실제 데이터를 적용해보고 내 모델을 만들어보기로 하였다.
Introduction
사실 지난 1월 anomaly detection 분야로 불량품을 탐지하는 해커톤 대회에서 감도 못잡고 끝냈던 것이 계속 언젠가는 이쪽을 공부해서 해결해야지 하는 마음이 있었다. 따라서 이번 수업을 통해 그 문제를 해결하고자 하였다.
(https://khw11044.github.io/project/2021-01-15-KUIAI/)[https://khw11044.github.io/project/2021-01-15-KUIAI/] 에서 데이터를 다운 받으면 되겠다.
먼저 내 프로젝트의 뿌리가 되는 논문인 (CLASSIFICATION-BASED ANOMALY DETECTION FOR GENERAL DATA)[https://github.com/lironber/GOAD#readme]에 대해서 간단히 설명하자면
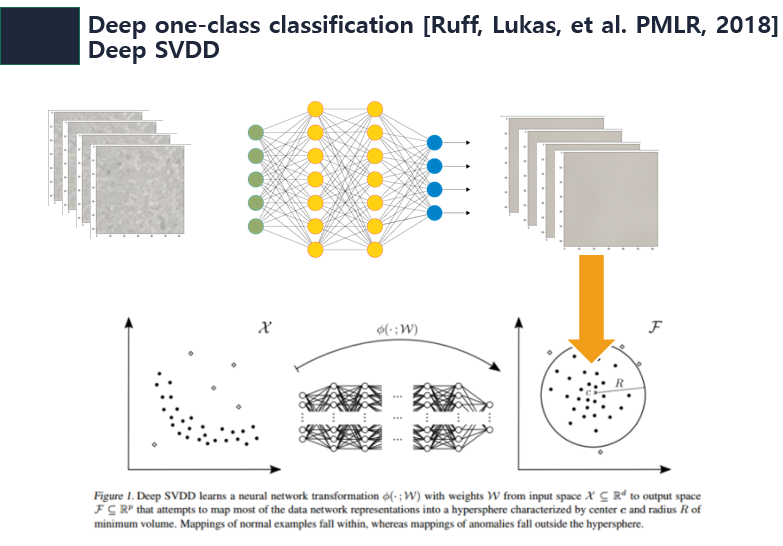 먼저 deep-svdd는 분포한 데이터를 커널을 통해 데이터를 설명할수 있는 새로운 분포를 만드는데 오른쪽과 같이 같은 class의 데이터들이 커널을 통해 하나의 원안에 포함되게 위치하게 된다. 원은 데이터들을 포함하면서 원이 최대한 작게 만들어지도록 학습하며 이때 커널을 DNN으로 구축한것이 deep-svdd이다.
먼저 deep-svdd는 분포한 데이터를 커널을 통해 데이터를 설명할수 있는 새로운 분포를 만드는데 오른쪽과 같이 같은 class의 데이터들이 커널을 통해 하나의 원안에 포함되게 위치하게 된다. 원은 데이터들을 포함하면서 원이 최대한 작게 만들어지도록 학습하며 이때 커널을 DNN으로 구축한것이 deep-svdd이다.
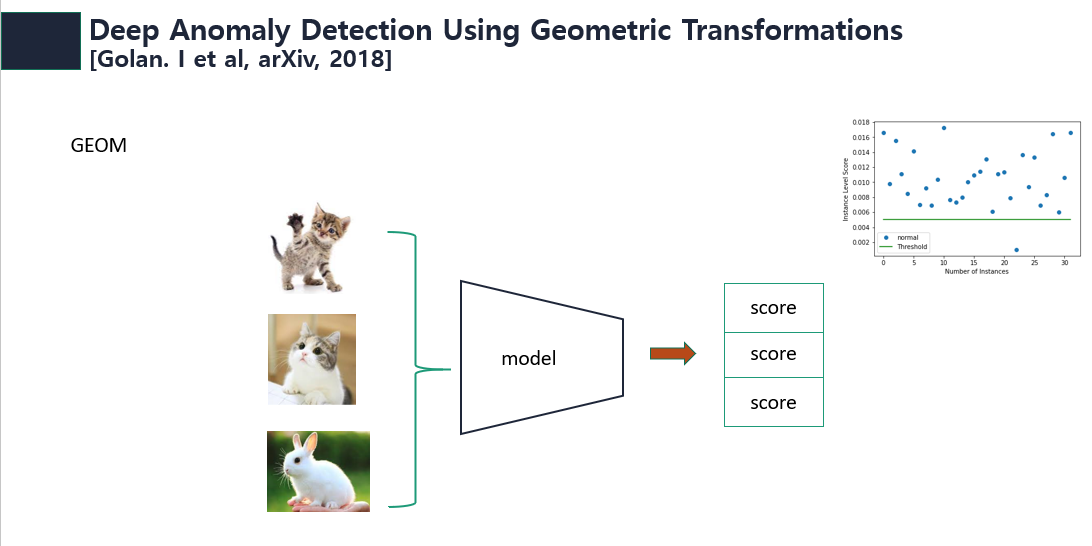
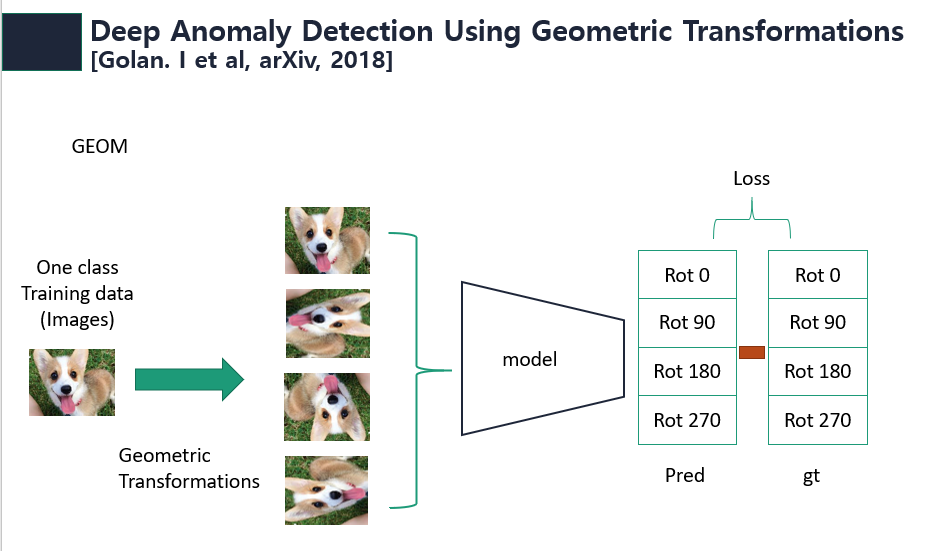 GOAD의 뿌리가 되는 GEOM(Deep Anomaly Detection Using Geometric Transformations)은 one class에 대해 Geometric trasformation을 통해 얻은 self-labeled와 data를 생성하고 일반적인 classifier를 학습시키고 classifier의 score로부터 정상, 비정상 여부를 판단한다. 이 방법은 classifier가 정상 데이터에 대해 Geometric trasformed된 이미지를 어떠한 transformation을 적용하였는지 잘 구분하게 학습하면 정상 데이터에 대한 공통된 feature를 얻을 수 있을 것이라는 동기에서 출발하였다. 따라서 아래 그림과 같이 정상 이미지에 대해서는 낮은 score를 output하고 비정상 이미지에 대해서는 높은 score를 output한다.
GOAD의 뿌리가 되는 GEOM(Deep Anomaly Detection Using Geometric Transformations)은 one class에 대해 Geometric trasformation을 통해 얻은 self-labeled와 data를 생성하고 일반적인 classifier를 학습시키고 classifier의 score로부터 정상, 비정상 여부를 판단한다. 이 방법은 classifier가 정상 데이터에 대해 Geometric trasformed된 이미지를 어떠한 transformation을 적용하였는지 잘 구분하게 학습하면 정상 데이터에 대한 공통된 feature를 얻을 수 있을 것이라는 동기에서 출발하였다. 따라서 아래 그림과 같이 정상 이미지에 대해서는 낮은 score를 output하고 비정상 이미지에 대해서는 높은 score를 output한다. 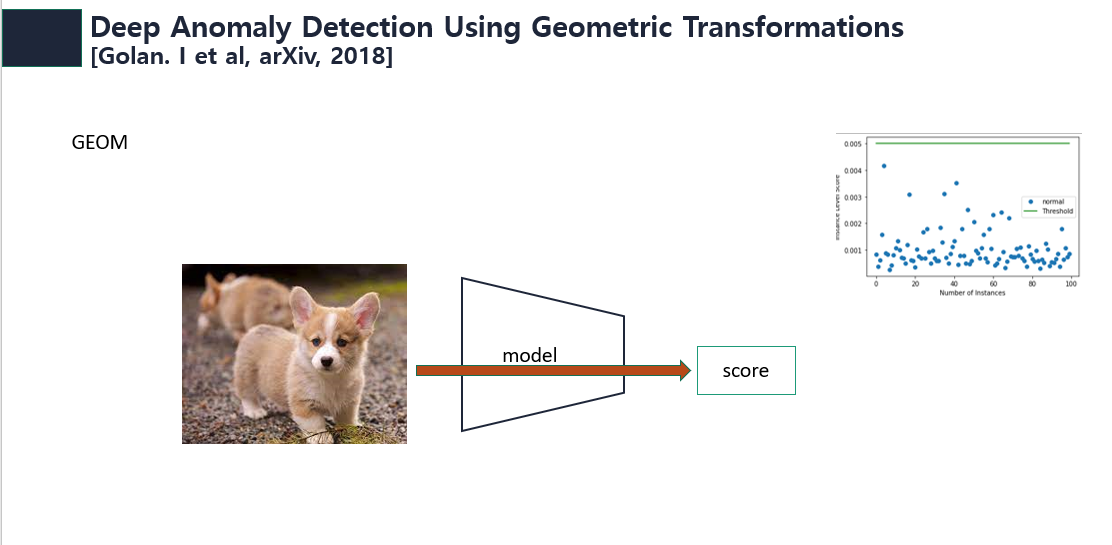
이런 GEOM을 tabular data에도 적용하기 위해 GOAD Geometric trasformation대신 affine transformation을 이용하였다. 또한 Deep-SVDD의 개념도 사용하였다. GOAD 구조는 아래 그림과 같다.
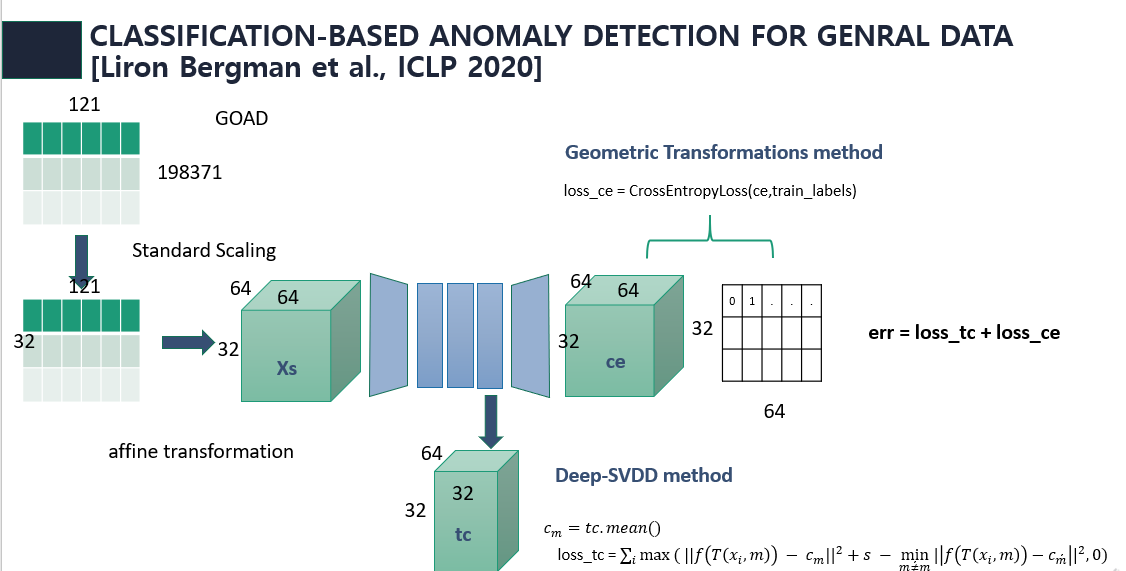
Experiments
나는 GOAD를 이용하여 KDD dataset을 실험해보았다. 기존 GOAD는 traing이 끝나면 f1 score만 output하며 어떤 추가적인 그래프나 모델저장이 되어있지 않았으며 dataset도 vaild dataset을 나누지 않았었다. 따라서 나는 이런것들을 모두 output하게 code를 custom하였다.
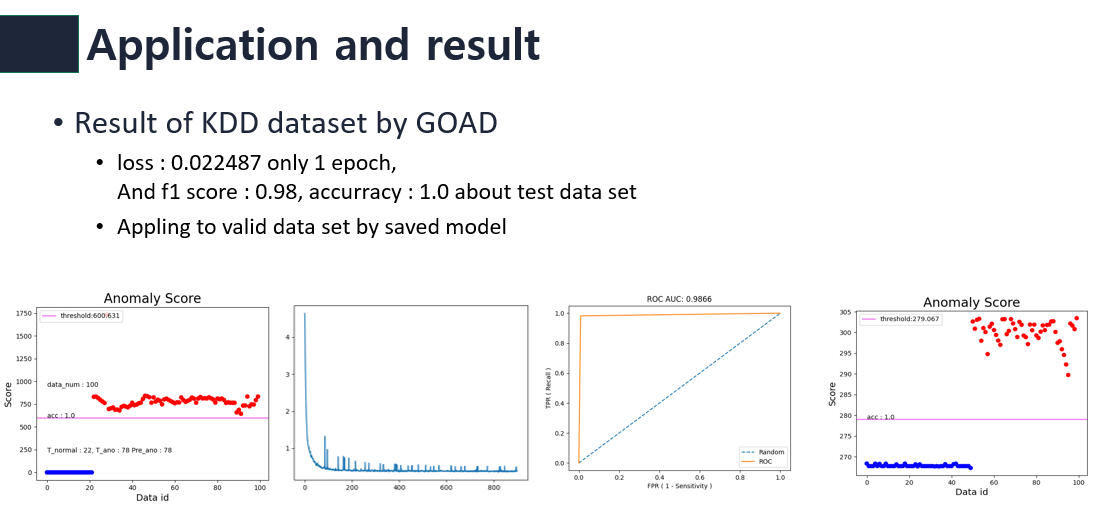
1 epoch만에 0.022의 loss값이 나왔으며 training이 끝나고 test dataset으로 실험해보니 f1 score가 0.98이였다. 저장한 모델을 이용하여 vaild data로 테스트해보아도 normal과 abnormal을 잘 구분하는것을 볼수 있다.
benchmark dataset을 테스트해본 이후 나의 첫 목표였던 해커톤 데이터를 적용해 보았다.
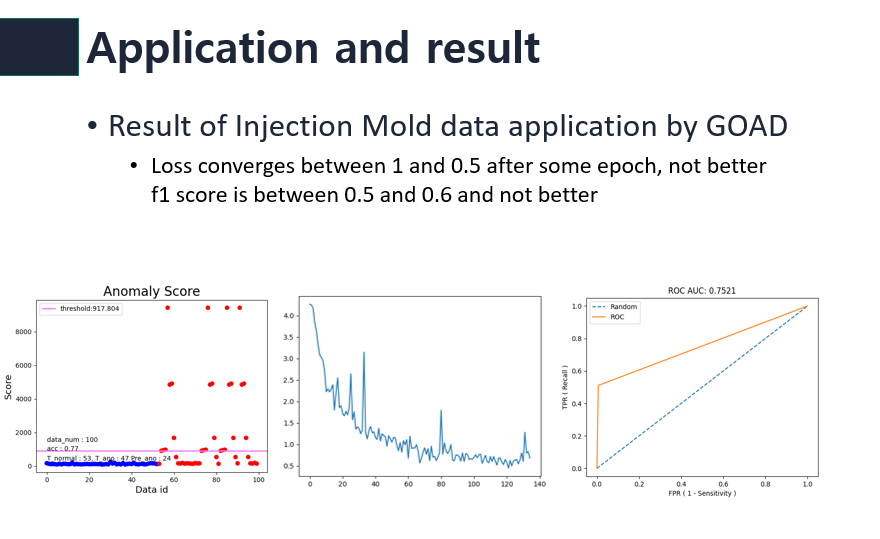
이상하게도 좋은 결과가 나오지 않았고 이것을 해결하기 위해서 많은 시간을 소비하였다. 실험 결과 그 해결방안은 training을 위해 데이터를 load하기전 preporcessing과정에서 데이터를 scale하는데 이때 기존 코드는 Standard scale을 사용하였다. 반면 해커톤 데이터의 경우는 MinMax scale을 사용하여야했다. MinMax scale을 통해 얻은 결과는 아래와 같다. 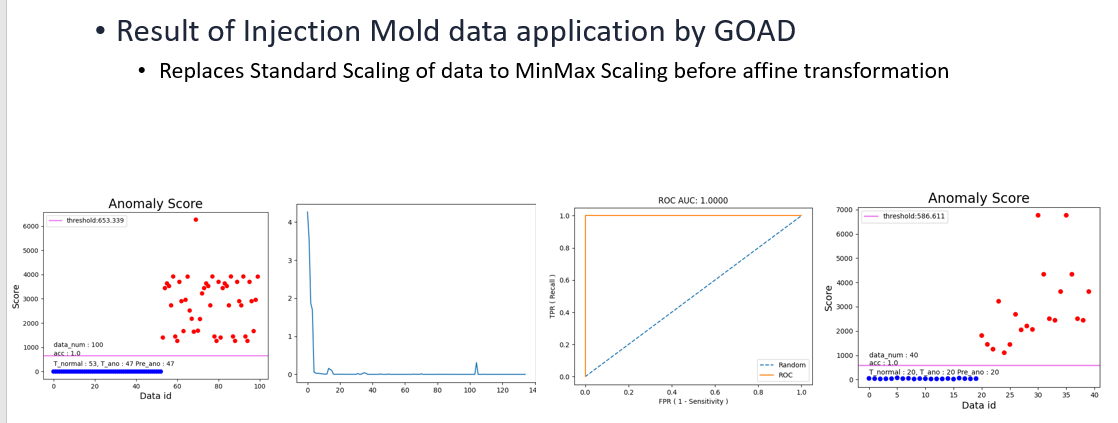
마찬가지로 좋은 결과를 얻게되었다.
이것으로 나의 첫 목표인 논문이 실 데이터에도 잘 적용하는가를 확인하였고 해커톤 대회 해결이라는 두개의 목표를 이루었다.
이후 나는 기말 발표를 위해 모델을 조금 바꿔보기로 하였다.
my propose
나는 classification-based method인 GOAD에 Reconstruction method를 적용해보기로 하였다.
기존 GOAD에 network를 AutoEncoder로 바꾸고 total loss에 reconstruction error를 추가해보았다.
먼저 나는 해커톤 대회 데이터를 AutoEncoder로 풀어보았다. 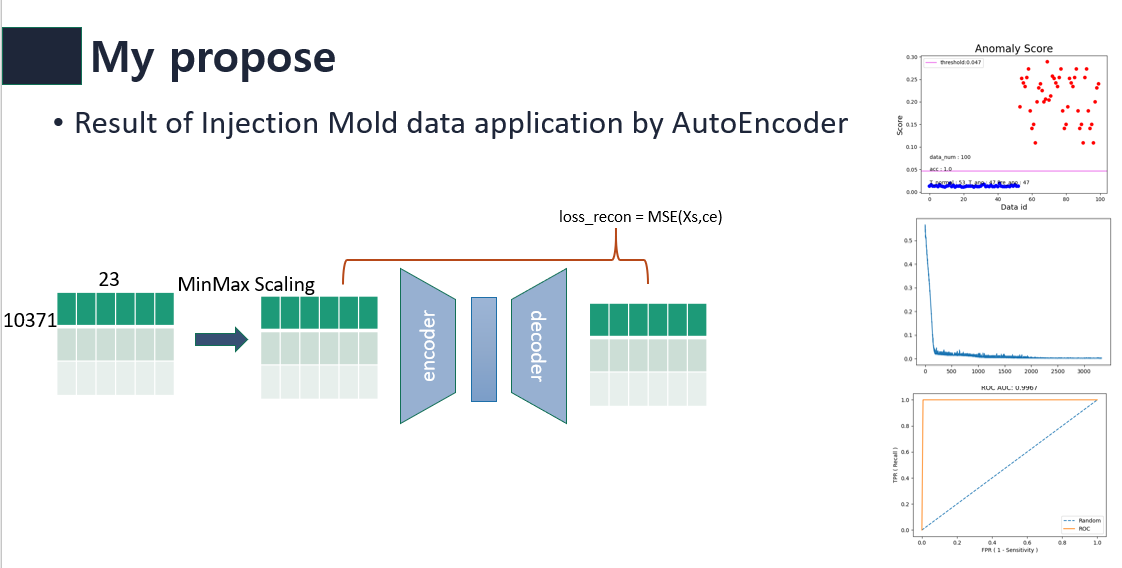 데이터를 affine transformation하지 않고 바로 batch size씩 AutoEncoder 모델에 넣으며 학습하였다. 아주 좋은 결과를 내었다.
데이터를 affine transformation하지 않고 바로 batch size씩 AutoEncoder 모델에 넣으며 학습하였다. 아주 좋은 결과를 내었다.
나는 affine trasnformed된 데이터를 AutoEncoder에 적용하는것도 좋은 결과가 나올것이라고 생각하였다. 하지만 결과는 아래 그림과 같이 좋지 않았다. 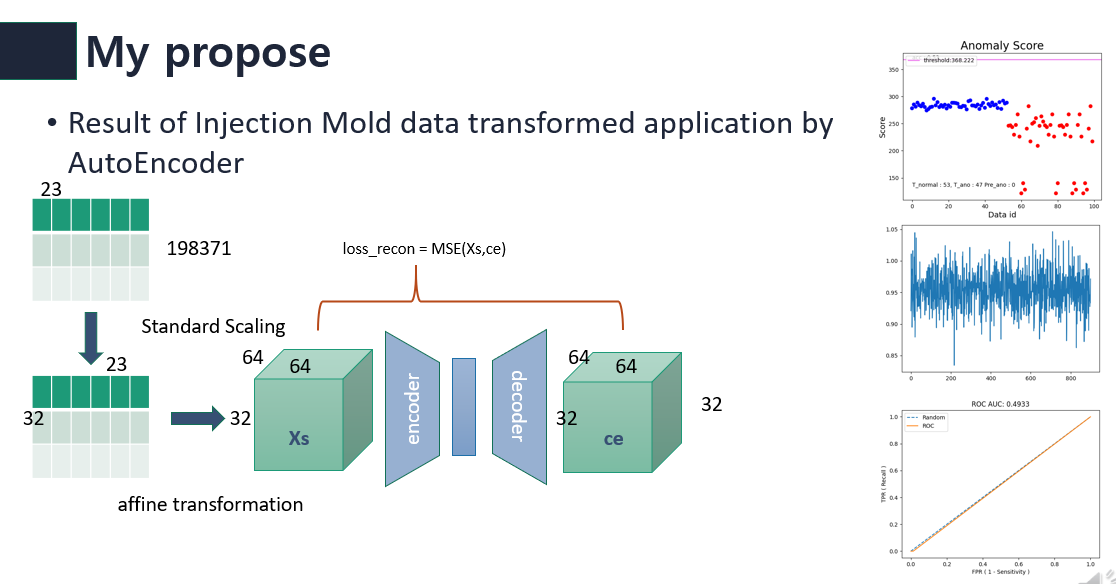
따라서 나의 첫 모델 구상은 역시 좋은 결과가 나오지 못하였다. 내 모델의 구조는 아래와 같다. 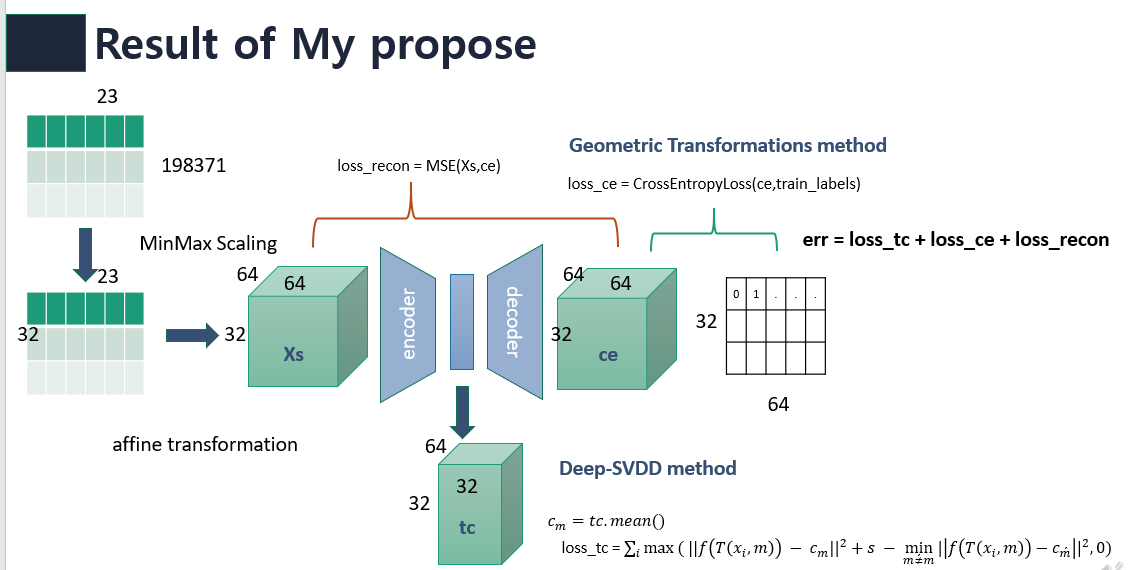
결과는 아래 그림과 같다. 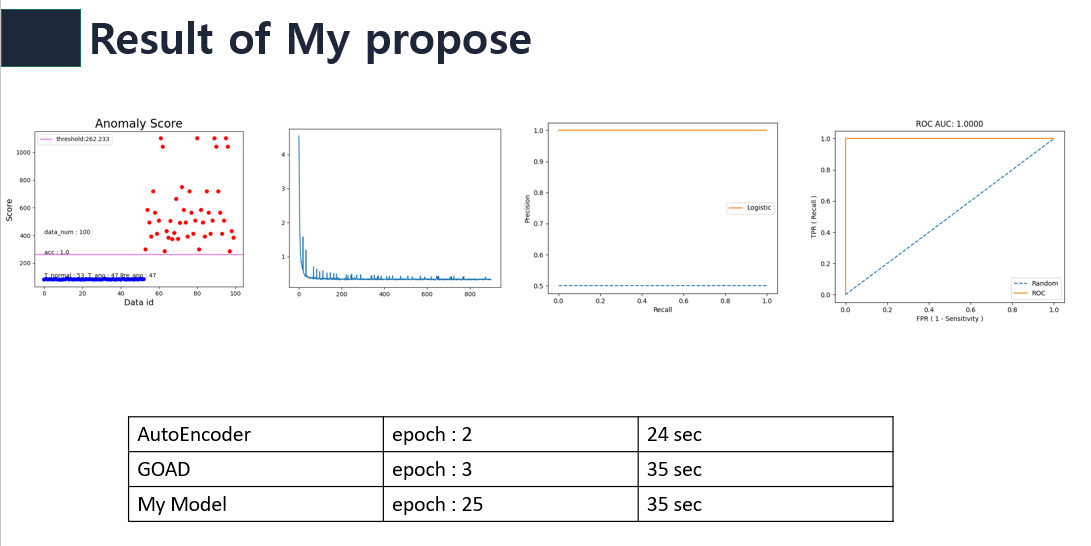 즉 내 모델은 기존 GOAD를 기반으로 하였기 때문에 결국 수렴하여 위와 같은 결과를 내보내지만 AutoEncoder 때문에 수렴하는데 더 오래걸렸다.
즉 내 모델은 기존 GOAD를 기반으로 하였기 때문에 결국 수렴하여 위와 같은 결과를 내보내지만 AutoEncoder 때문에 수렴하는데 더 오래걸렸다.
니는 transformed된 데이터에 AutoEncoder network와 reconstruction error를 축가하는 것이 분명 의미가 있다고 생각한다. 나중에 시간이 되면 더 공부하고싶다.