A-NeRF:
Articulated Neural Radiance Fields for Learning Human Shape, Appearance, and Pose
2021 paper
Shih-Yang Su
Frank Yu
Michael Zollhöfer
Helge Rhodin1
Abstract
Deep learning은 classical motion capture pipeline을 feed-forward networks로 다시 만드는 동안, generative models는 iterative refinement를 통해 fine alignment를 recover하는 것을 요구받는다. 불행하게도, 기존 모델들은 보통 hand-crafted되거나 또는 통제된 조건에서 learned되고 오로지 제한된 domains에서 적용가능하다. 우리는 unlabelled monocular videos로부터 확장된 Neural Radiance Fields (NeRFs)를 통해 generative neural body model을 학습하는 method를 제안한다. 우리는 그것들에 시시각각 움직임(time-varying)과 관절운동(articulated motion)에 적용할 skeleton(골격)을 갖추었다.
Key insight는 implicit models가 explicit surface models에 시용되는 the inverse of the forward kinematics를 요구한다는것이다. 우리의 reparameterization은 body parts의 pose에 관련된 spatial latent variables를 정의하고 그것에 의해 overparameterization을 갖는 ill-posed inverse operations를 극복한다. Jointly하게 articulated pose를 refining하는동안 이것은 밑바닥부터 volumetric body shape과 appearance를 학습하게 해준다; input videos에 대해 appearance, pose, 또는 3D shape에 대해 전부 ground truth labels가 없다. Novel-view-synthesis와 motion capture에 대해 사용할때, 우리의 neural model은 다양한 datasets에 대해 정확성을 향상시킨다.
1 Introduction
Generative models는 image를 재생성하는 Generative Adversarial Networks (GANs)에서 structured latent variables를 통해 downstream tasks에 대해 이해하는 control과 image를 제공하는 neural scene representations로 차츰 발전해오고 있다. 그러나, 대부분 3D models는 natural images에서 3D labels를 요청하고 dedicated depth sensors를 요청하다.
따라서 2D observations로부터 3D representations를 학습하는것은 중요한 연구문제이다, 이것은 특히 사람의 다양한 body shapes 그리고 appearances 그리고 non-rigid motion에 대한 어려움이 있다.
Modern human motion capture techniques는 전형적으로 discriminative approach와 generative approach의 장점을 combine한다. Feed-forward 3D human pose estimation approach는 human pose의 rough initial estimate를 제공한다. 이후, person의 high-quality 3D scan 또는 laser scans로부터 학습된 parametric human body model 중 하나를 기반으로 하는 generative approach는 image evidence 기반으로 iteratively하게 estimate를 refine한다. 비록 기존 모델들은 유례없는 정확도를 성취하였지만, 기존 모델들은 user의 low-dimensional, restrictive, shape body model 또는 personalized 3D scan 을 요구한다.
우리는 unlabelled videos에서 user-specific neural 3D body model을 learning하고 skeleton pose를 이해하는 Articulated Neural Radiance Fields (A-NeRF)를 소개한다. 이것을 motion capture에 적용할때, template models의 필요성을 줄이는 동시에 현재 generative approaches의 장점과 정확성을 유지한다. A-NeRF는 Neural Radiance Fields (NeRF)를 single videos와 articulated motion 작업으로 확장한다. A-NeRF는 scene을 implicitly(절대적으로) 다음과같이 parameterize한다. \[F_{\phi}(\Gamma(\mathbf{q}),\Gamma(\mathbf{d})) \mapsto (\sigma,\mathbf{c}), \qquad \text{with} \; \sigma \in \mathbb{R}, \mathbf{c} \in \mathbb{R}^3, \mathbf{q} \in \mathbb{R}^3, \; \text{and} \; \mathbf{d} \in \mathbb{R}^3\]
\(F_{\phi}\)와 Multi-layer Perceptron (MLP) with \(\Gamma\), Positional Encoding (PE)를 chaining함으로써. 첫째, PE는 input scene point \(\mathbf{q}\)와 view direction \(\mathbf{d}\)를 higher dimensional space로 mapping한다. Higher dimensional space는 공간상의 모든 point에 radiance c와 opacity \(\sigma\)를 순차적으로 output하는 meaningful scene representation function \(F_{\phi}\)를 MLP가 학습할 수 있게 해준다.
둘째, (query locations에 대한 conditioning을 통해) implicitly described scene이 computer graphics로부터 classical ray-marching을 통해 rendered된다. MLP representation의 장점은 그것이 volumetric grids의 complexity를 피하고, screen-space convolution의 implicit bias에 의해 일어나는 artifacts를 회피하고 surface meshes와 달리, flexible topology를 갖을 수 있다. 그러나, original NeRF는 오직 multiple views에서 보이는 각 3D point와 같은 calibrated cameras의 dozens로부터 포착되는 static scenes에만 작동된다.
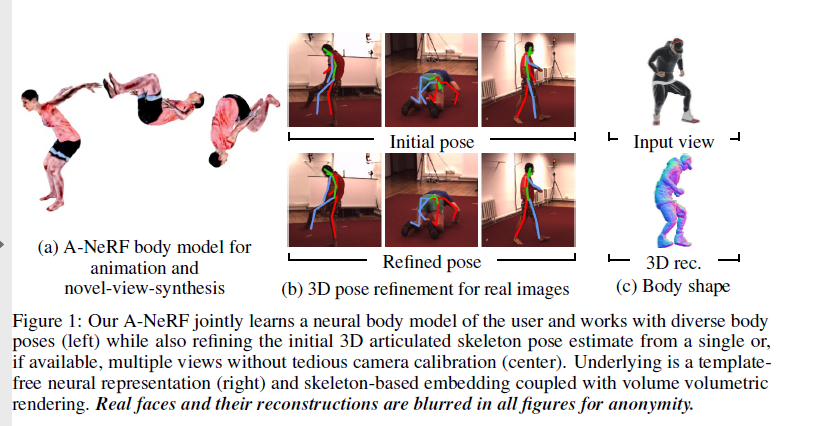 Figure1 : 우리의 A-NeRF는 jointly하게 user의 neural body model을 learn하고 다양한 body poses에 작동한다(a). 또한 tedious camera calibration없이 single 또는 가능하면 multi-views에서 initial 3D articulated skeleton pose estimate를 refining한다(b). 기본에는 template free neural representation(c)과 volume volumetric rendering과 결합된 skeleton-based embedding이 있다.
Figure1 : 우리의 A-NeRF는 jointly하게 user의 neural body model을 learn하고 다양한 body poses에 작동한다(a). 또한 tedious camera calibration없이 single 또는 가능하면 multi-views에서 initial 3D articulated skeleton pose estimate를 refining한다(b). 기본에는 template free neural representation(c)과 volume volumetric rendering과 결합된 skeleton-based embedding이 있다.
우리의 개념적 contribution은 articulated skeleton과 관련된 neural latent representation을 학습하는것에 놓여있다. 인기있는 SMPL body model과 같은 explicit models는 forwards kinematics를 통해 surface를 변형시키는 반면, A-NeRF의 implicit form은 우리에서 어떻게 skeletons가 어떻게 integrated될 수 있는지를 다시 생각하게 해준다 – implicit networks는 3D world coordinates부터 완전히 탐구되지 않은 상당히 어려운 task인 reference skeleton까지 inverse transformation을 요구한다. 우리의 core technical novelty는 articulated skeleton에 관련된 local coordinates를 만들어내기 위해 수식 1에서 \(\Gamma(q)\), \(\Gamma(d)\)의 different parameterizations을 찾아내는것이고 평가하는것이다. 3D world coordinates에 point는 body part에 유일하게 연결될수 없기 때문에 우리는 뼈당 하나로 embedding에 overparameterizing에 의한 mentioned ill-posed inverse problem을 해결한다. 이것은 인간 움직임 방법의 도메인 지식을 embed하고 neural network가 entire captured sequence에 걸쳐 body shape과 appearance constraints를 combine하는 common frame을 제공한다(그림2 참고).
우리는 우리의 모든 contributions가 이전에 parametric surface models 또는 multi-view approaches을 통해서만 얻었던 세부 수준에 도달하는 초기 rough한 3D pose estimates만 필요로하는 monocular video에서 neural body model을 학습할 수 있다는 것을 증명한다.
Scope(범위/한계). 우리는 모델을 motion capture, character animation, 그리고 appearance 그리고 motion transfer에 적용하고 pose refinement가 existing monocular skeleton reconstruction에 제공됨을 시연한다. 우리는 transductive setting에서 training time은 알지만 ground-truth는 가지고 있지 않는, specific target video에 대해 learn한다. A-NeRF는 non-physical illumination인 그럴듯한 dynamic motions의 novel view synthesis를 할수 있다. relighting applications을 할려면 추가적인 steps가 필요하다.
General impact Personalized human body modeling의 self-supervised approach를 구축하면 supervised datasets에 잘 represented되지 않는 사람과 활동에 더 많이 포괄될 수 있다. 그러나, 동의 없이 사람의 3D models이 만들어질 수 있다는 위험은 감수하고 있다. 우리는 사용자가 오로지 motion capture algorithms를 개발하고 평가하기위해 수집된 datasets만 사용할 것을 권한다.
2 Related Work
우리의 approach는 human pose, shape estimation, human modeling, 그리고 neural scene representations에 대한 다음 연구를 기반으로 하며 이와 관련이 있다.
Discriminative Human Pose Estimation.
3D joint positions 또는 skeleton의 joint angles와 bone length [56,77]의 feed-forward estimation은 상당히 정확한 반면, generalization gap때문에 input image에 overlayed될때 discriminative estimates는 misalignment하는 경향이 있다.
skeleton pose는 2D pose estimates에 잘 match되게 refine 될 수 있지만, 이것은 보통 3D에 large errors를 야기한다 [39,40].
우리는 skeleton pose를 초기화하는데 사용하고 그것을 neural body model과 combine한다.
Surface-based Generative Body Models
Surface-based Generative Body Models는 deformation energies를 통해 template meshes에 제약을 가하는것(constraining) 또는 laser scans의 large collection으로부터 parametric human body models를 learning하는것 둘 중 하나로부터 얻어진다.
그것들의 low-dimensional parameters는 그럴듯한 human shapes와 motions의 공간에 제약을 가한다(constrain). 이것은 single images, detailed texturing과 displacement mapping [4, 6], 그리고 alleviates manual rigging [3]로부터 real-time reconstructions를 가능하게해준다 [8,18].
그것은 또한 differentiable form [30]로 neural training processes[5,23,26,45,48,68]에 통합될 때 학습된 prior [14,19,28]과 weak-supervision의 범위안에서 optimization이 가능하게 한다.
이 범주에서 우리의 approach에 가장 가까운 것은 untextured parametric quadruped model을 얼룩말 이미지로 textures하고 기하학적으로 refines하는 [79]와 optical flow을 사용하여 human pose를 refine하는 [72]의 model fitting methods이다.
비록 비슷한 setting이라도, 우리의 surface-free neural body model과 volumetric rendering은 forward kinematics가 갖춰져있고 a-priori가 얻어질 필요가 있는 textured triangle mesh와 근본적으로 다르다.
Implicit Body Models.
A-NeRF는 differentiable ray-tracing을 통해 human pose, shape, 그리고 appearance를 refining 하는데 사용되는 level-sets[61] 와 density of a sum of Gaussians [21, 51, 52]의 측면에서 암묵적(implicitly)으로 정의된 body models와 유사성을 가지고 있다.
Neural Scene Representations
최근 neural scene representations는 mesh [31,66], point clouds [2,41,71], sphere sets [27], 그리고 dense volumetric grids [32,58]의 low-dimensional nonlinear representations을 학습한다.
그것들의 respective geometric output representations은 classical rendering techniques를 사용하여 rendering이 가능하게 하지 expressiveness에 제약이 있다, 예를들어, surface mesh의 고정된 connectivity와 discretized(이산화된) volumes의 large memory footprint 때문이있다. 이 한계는 3D 공간에서 임의의 point를 특징짓기 위해서 positional encoding[63]과 쌍을 이루는 unconstrained MLPs [42]를 사용함으로써 극복되었다.
sphere tracing [59]으로 rendered되는 MLP의 level-sets를 통한 surface definitions와 ray-marching을 통해 rendered되는 density representations [42]이 일반적이다.
rendering step은 maximum likelihood estimation를 위해, 3D model를 learning하는동안 관찰되는 variables -실제 이미지 -에 걸친 likelihood를 정의하기위해 필요하다.
rendering 역시 학습될 수 있다[43, 53, 54] 하지만 보통 불일치(inconsistencies)가 발생한다, 특히 training data가 희박할때.
몇몇 동시대의 연구들은 또한 camera motion [75], video reenactment [50], facial models [15, 16]을 refining 하기 위해 neural scene representations을 사용한다.
이런 연구들과 직교하게, 우리의 A-NeRF는 estimated poses와 uncalibrated cameras로부터 articulated body model을 학습한다.
우리의 것과 밀접한 관련이 있는 NASA surface body model [13]은 implicit function을 skeleton의 뼈에 견고(rigidly)하게 부착되는 individual implicit functions의 최소로 정의하며, 각각 모델 의존성에 대한 전체 human pose에 따라 조절되고 3D scans로부터 학습된다.
반대로, 우리는 surface model대신에 volumetric model를 학습하고 appearance와 rendering을 포함한다.
훨씬 더 비슷한것은 최근 NeuralBody[49] representation인데 이것은 NeRF를 surface body model과 기본 skeleton과 결합한다.
두 approaches와 대조적으로, 우리는 surface supervision이나 initialization, condition pose differently, 그리고 refine pose 이 필요하지 않고 우리가 unconstrained environments에서의 single videos로부터 학습할 수 있게 해준다.
Formulation
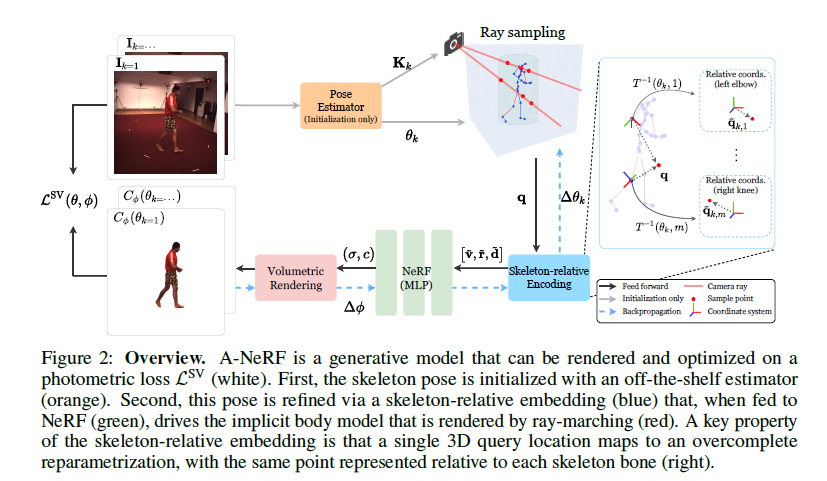 Figure2 : Overview. A-NeRF는 rendered될 수 있고 photometric loss \(\mathcal{L}^{SV}\)에 optimized 될 수 있는 generative model이다(white). 첫쨰, skeleton pose는 기존의 estimator에의해 initialized 된다(orange). 둘째, 이 pose는 skeleton-relative embedding를 통해 refine된다(blue). 그리고 그것이 NeRF에 넣어진다(green), 그리고 ray-marching에 의해 rendered되는 implicit body model을 이끌어낸다(red). skeleton-relative embedding의 key property는 single 3D query location이 overcomplete reparameterization에 mapping한다, 각 skeleton bone에 관련하여 represented된 같은 point와 함께(right).
Figure2 : Overview. A-NeRF는 rendered될 수 있고 photometric loss \(\mathcal{L}^{SV}\)에 optimized 될 수 있는 generative model이다(white). 첫쨰, skeleton pose는 기존의 estimator에의해 initialized 된다(orange). 둘째, 이 pose는 skeleton-relative embedding를 통해 refine된다(blue). 그리고 그것이 NeRF에 넣어진다(green), 그리고 ray-marching에 의해 rendered되는 implicit body model을 이끌어낸다(red). skeleton-relative embedding의 key property는 single 3D query location이 overcomplete reparameterization에 mapping한다, 각 skeleton bone에 관련하여 represented된 같은 point와 함께(right).

Figure 3: Importance of our skeleton-relative encodings. (a) original NeRF는 poses의 다양한 set을 훈련하면 (a)처럼 깨지고 더욱이 (b)에서는 pose를 회전하면 더욱 품질이 떨어진다.(e)는 직접적으로 \(\theta_k\)을 조건화되었지만 NeRF는 human articulation의 complexity와 ambiguity 때문에 여전히 artifacts에 고통받는다. 우리의 skeleton-relative encoding (f,g)와 함께, subject의 geometry는 rotation에 대해서 일관되고 quality는 상당히 향상된다.
Objective
같은 사람에 대한 하나 또는 여려개이 비디오에서 나오는 images \(\mathbf{I}_k \in \mathbb{R}^{H \times W \times 3} \;\) N개인 sequence \([\mathbf{I}]^N_{k=1}\)를 고려하면, 우리의 goal은 시시각각 변하는 skeleton poses \([\theta]^N_{k=1}\)을 동시에 estimate하고 상세한 body model을 learn한다.
우리의 A-NeRF body model \(C_{\phi}\)는 volumetric shape과 color를 정의하는 neural network parameters \(\phi\)에 의해 parametrized된다.
그림2는 generative model의 overview를 보여준다.
이것은 보이지 않는 poses에 virtual body model의 rendering을 가능하게 하고 image reconstruction objective에 그것의 parameters \(\theta\)와 \(\phi\)가 optimize한다. \[\mathcal{L}^{SV}(\theta,\phi) = \sum_k ||C_{\phi}(\theta_k) -\mathbf{I}_k||_1 + \lambda_{\theta} d(\theta_k - \hat{\theta_k}) + \lambda_t \left \Vert \frac{\partial^2 \theta_k}{\partial t^2} \right \Vert ^2_2 \tag{2}\]
data term, pose regularizer, smoothness prior
hyperparameters \(\lambda_t\)와 \(\lambda_\theta\)에 의해 균형잡힌 3개 terms 모두의 influence과 함께.
data term은 \(C_{\phi}\)에 의해 generated된 images들과 input image 사이의 distance를 L1 distance로 측정한다
pose regularizer는 solution이 기존 predictor [26]에 의해 얻은 initial pose estimate $\hat{\theta}$에 가깝게 해준, 허용되는 small shifts $$\epsilon = 0.01$ with $d(x) = \text{min}( x ^2_2 - \epsilon,0)$$. - smoothness prior은 연속 frames의 poses간의 acceleration \(\frac{\partial^2 \theta_k}{\partial t^2}\)에 패널티를 준다. 수식2를 최소화 하는것은 quadratic energy terms가 Gaussian distributions의 log-likelihoods인 corresponding probabilistic model를 최대화 하는것으로 볼수 있다.
우리의 focus는 neural body model을 수식화하는것이다. 간단하게, 우리는 stochastic gradient descent하면서 inference하는동안 사용되는 objective functions에 관련된 방정식을 계속해서 쓴다.
3.1 NeRF and A-NeRF Image Formation Model
scene을 a collection of triangles이나 other primitives로 modeling 하는것 대신에, 우리는 neural network에 의해 human implicitly를 공간의 가능한 모든 3D points들과 view directions에 정의된 function(수식1)로 정의한다 [42].
NeRF와 유사하게, 우리는 ray marching을 통해 human subject의 image를 render한다. \[C_{\phi}(u,v;\theta_k) = \sum^Q_{i=1}T_i(1 - exp(-\sigma_i\delta_i))\mathbf{c}_i, \quad T_i=\text{exp} \left (-\sum^{i=1}_{j=1} \sigma_j \delta_j \right), \tag{3}\]
여기서 \((u,v)\)는 image에서 2D pixel location이고 $\mathbf{d}$에 따라 샘플된 3D query positions \(\mathbf{q}_i\)까지 index i, 그리고 neighboring samples간의 거리인 \(\delta_i\) - a constant if samples would be taken at regular intervals.
\(T_i\)는 near plane부터 \(\mathbf{q}_i\)-fraction of light reaching the sensor from sample point $i$까지 ray traveling에 대한 accumulated transmittance(누적 투과율 )이다.
\(c_i\)는 \(i\)에서 방출(emitted)되거나 반사(reflected)된 light color이다.
최종 pixel color는 모든 Q samples들에 걸친, background의 special role을 취하는 마지막 sample로 모두 sum한것이다. background color는 static camera setups에서 전체 비디오에 걸친 median pixel color를 통해 쉽게 추론된다. 그다음, 우리는 우리이 skeleton parametrization \(\theta_k\)와 어떻게 이것을 dynamic articulated human motion에 효과적으로 모델링하는데 사용할 수 있는지를 소개한다.
3.2 Articulated Skeleton Pose Model
우리의 skeleton representation은 connectivity와 static bone lengths를 3D joint locations의 rest pose를 통해 encoding한다.
Dynamics are modeled with per-frame skeleton poses, which define an affine transformation for each bone.
Dynamics은 각 뼈 \(m\)에 대한 affine transformation \(T(\theta_k,m)\)을 정의하는 프레임별 skeleton poses\(\theta_k\)로 모델링된다.
특히, \(T(\theta_k,m)\)은 m번째 local bone coordinates의 3D position \(\mathbf{p}_{k,m} \in \mathbf{R}^3\)를 world coordinates \(\mathbf{q} \in \mathbb{R}^3\)로 매핑한다, homogeneous coordinates를 사용해서, \[\begin{bmatrix} \mathbf{q} \\ 1\end{bmatrix} = T(\theta_k,m) \begin{bmatrix} \mathbf{p}_{k,m} \\ 1\end{bmatrix}, \; \tag{4}\]
subscript \(_{k,m}\)은 variable이 image \(\mathbf{I}_k\)의 m번째 joint와 관련있음을 나타낸다.
반대로, \(T(\theta_k,m)^{-1}\)은 world coordinate에서 local bone coordinate로 매핑한다.
우리의 skeleton은 SMPL등과 같다, 그러나 parametric surface model이 없고 그러므로 어떤 skeleton pose estimator로 초기화될수 있다.
우리는 supplementary에서 우리의 skeleton representation의 더 자세한 세부사항을 담아놨다.
3.3 A-NeRF Skeleton-Relative Encoding
우리의 핵심 contribution은 NeRF를 통해 transformed되는 지점의 color와 opacity가 결정되기 전에 skeleton과 관련된 query locations \(\mathbf{q}\)와 view direction \(\mathbf{d}\)를 transform 하는 것이다.
이것은 human body parts가 서로 어떻게 연결되고 변형되는지에 대한 도메인 지식을 명시적으로 통합하는 reparameterization의 한 형태이다. 직관적으로, 그것의 머리에서 우리의 implicit formulation은 SMPL과 같은 explicit models로 바꾼다.
skinning을 통해 output surface를 변형하는것 대신에, query location은 NeRF network를 통과하는 과정을 거치기전에, inverse direction에서 local bone-relative coordinate system으로 매핑된다. 우리의 최종 모델은 결합된 encoding \(\text{e}_k = [h(\tilde{v})k)\Gamma(\tilde{v}_k),\tilde{r}_k,h(\tilde{v}_k)\Gamma(\mathbf{d}_k)]\) 를 NeRF \(F_{\phi}\)에 input으로 사용한다.
skeleton embedding은 subscript \(k\)로 표기된 desired time dependency를 도입한다는 점에 유의해라.
inlet은 우리의 가장 중요한 기여를 보여주는데, relative distance encoding \(\tilde{v}_k\)에 이어 irrelevant bones의 영향을 줄이기 위해 컷오프(Cutoff)를 사용한 PE가 뒤따른다.
우리는 우리의 encoding \(\text{e}_k\)의 구성요소와 밑에 다른 대안들을 이끌어낸다.
Reference Pose Encoding
frame \(k\)에서 world coordinates의 query \(\mathbf{q}\)를 가장 가까운 뼈 \(m\)에 부착하고 그것을 다음과 같이 transforming함으로써 움직임을 보정할 수 있다. \[a_k = T(\theta_0, m) T^{-1}(\theta_k,m)\mathbf{q} \tag{5}\]이렇게 하면 frame \(k\)에서와 같이 뼈 m에 상대적인 query가 배치되지만 skeleton은 정지자세(rest pose) \(\theta_0\) 이다.
그러면 NeRF는 surfaces에서와 같이 rest pose의 3D 공간에서 변화 없이 learn할 수 있다.
그러나, 이것은 muscle bulging과 같이 non-rigid pose depedent effects를 갭쳐 할 수 없고 \(\mathbf{q}\)가 2개의 뼈와 같은 거리에 있을때 ambiguities를 갖는다.Bone-relative Position (Rel. Pos.)
3개의 ambiguities와 ill-posed association을 제거하기 위해서, 우리는 각 뼈 \(m\)에 관련된 \(\mathbf{q}\)를 다음 수식으로 매핑한다, \[\tilde{q}_k = [\tilde{q}_{k,1}, ..., \tilde{q}_{k,24}] \; \text{and} \; \tilde{\mathbf{q}}_{k,m} = T^{-1}(\theta_k,m)\mathbf{q} \tag{6}\]resulting individual bone coordinates는 해당하는(corresponding) body part의 overwhelmingly rigid motion을 모델링 하기에 아주 적합하다. 게다가, 모든 local encodings을 concatenating한 position의 overparameterization는 complex interactions이 필요할때 학습을 가능하게 한다.
그러나, 이런 모든 뼈에 대한 embedding은 크기 순으로 dimensionality가 증가한다.Relative Distance (Rel. Dist.) 훨씬 간단하게 계산할 수 있는것은 \(\mathbf{q}\)에서 모든 뼈들 \(m\)까지의 distances이다,
이 radial encoding은 spherically shaped limbs를 자연스럽게 캡처하고, lower-dimensional적이며, 따라서 reconstruction accuracy를 향상시키기 때문에 \(\tilde{\mathbf{q}}\)에 유리한 최종 모델에 사용된다.
- Relative Direction (Rel. Dir.)
distance encoding은 direction에 불변이기 때문에, 우리는 \(\mathbf{q}\)의 orientation 정보를 capture하기위해 추가적으로 direction vector를 얻는다,
다른 모든 embeddings와 달리, direction encoding은 후속 PE에서 이익을 얻지 못하였다. 그러므로 우리는 그것을 직접적으로 \(\text{e}_k\)에 통과시켰다.
- Relative Ray Direction (Rel. Ray.)
NeRF는 position과 view direction을 이용해서 고정된 3D scene에 대해 조명효과(illumination effects)를 모델링한다.
반대로, 우리의 목표는 dynamic skeleton poses에 그럴듯한 colors를 생성하는 body model을 학습하는것이다. 따라서 우리는 \(\mathbf{d}\)를 transform하여 query position과 유사한, 각 뼈에 대한 outgoing ray direction인 \(\tilde{\mathbf{d}}\)를 얻는다.
\([T^{-1}(\theta_k, m)]_{3 \times 3}\)는 bone-to-world transformation \(T^{-1}(\theta_k, m)\)의 rotational part이다.
다음 concurrent works[36,49]에 따라, 우리는 dynamic light effects를 다루기 위해 각 image에 appearance code를 optimize한다.
\(\tilde{\mathbf{d}}\)와 per-image code의 조합은 A-NeRF가 \(\mathbf{I}_k\)에 light effects를 그럴듯하게 approximate하게 한다. view-dependent effects를 모델링하는것에 대한 detailed discussions 에 대한 supplemental material를 봐라
- Cutoff
우리는 points가 근처 뼈에 의해서만 영향을 받지 않아야 하는 local embedding을 원한다.
결과적으로, 우리는 \(h(\tilde{\mathbf{v}}_{k,m}) = 1 -S(\tau(\tilde{\mathbf{v}}_{k,m}-t))\)에 의해 뼈 \(m\)에 관한 encoding을 곱(multiplying)함으로써 positional encoding의 windowed version을 소개한다, \(S\)는 sigmoid step function, \(t\)는 cutoff point, \(\tau\)는 sharpness.
이것은 distant bones에 영향을 받지않는 queries를 떠난다.
\(\mathbf{e}_k = [h(\tilde{\mathbf{v}}_k) \Gamma(\tilde{\mathbf{v}}_k), \tilde{\mathbf{r}}_k, h(\tilde{\mathbf{v}}_k) \Gamma(\tilde{\mathbf{d}}_k)]\)의 our embedding choice는 person의 global shift와 rotation이 불변하는것의 장점을 가지고 있고 pose-dependent deformation가 여전히 가능하면서 piece-wise rigidity of articulated motion을 보존한다(그림3참고). \(\mathbf{e}_k\) 뿐만 아니라, 우리는 또한 다른 embeddings variants를 고려한다. 더 자세한것은 supplementary와 Section 4를 참고하라.
4 Evaluation
우리는 A-NeRF가 관련된 연구보다 더 적은 가정 (single view, uncalibrated, w/o a parametric surface model)에서 정확한 body models와 poses를 학습할수 있음을 증명하기위해 실험을 수행하였다.
이것은 그것이 최신 methods들의 estimates를 향상시키는 fine-grained pose refinement에 적용가능하게 한다.
supplements는 세부사항 수행을 제공하고 추가적인 비교와 ablation studies를 제공한다.
Inference and Implementation Details
우리의 A-NeRF model은 같은 사람의 single 또는 multiple videos에 supervision없이 학습된다.
setting \(\mathbf{a}_m\) 그리고 pose \(\theta_k\) 에 대한 Camera intrinsics, bone lengths는 모든 frame \(k\)에 [26]로 초기화된다.
그런다음 이런 poses는 generative A-NeRF model과 함께 objective 수식2에 optimized된다. supplementary 참고
Datasets.
우리는 다음 benchmarks, 추가적으로 SURREAL과 Mixamo characters로 만든 synthetic data에 에 evaluate한다.
Human 3.6M [22] 이 dataset은 5개의 training과 2개의 testing subjects(S9/S11)로 ground truth 3D joint locations와 함께 구성되어있다. 우리는 넓게 채택된 2개의 test protocols인 Protocol I [23,25,26]과 Protocol II [44,62]를 따른다, 이것은 우리가 각각 test videos의 매 5번째/64번째의 14/17-joint estimation error를 평가한다. supplement참고
MPI-INF-3DHP [38] 이 dataset은 human pose estimation에 표준 benchmark이다. 이것은 challenging human poses에 4개의 실내 2개의 실외 subjects로 이루어져있다. subject당 frames수는 276부터 603개의 범위를 갖는다.
MonoPerfCap [74] 이 dataset은 실내와 실외 settings 모두에 대해 단일 카메라로 촬영된 human performance video로 구성되어있다. 우리는 2개의 subjects를 사용한다, Weipeng_outdoor와 Nadia-outdoor, 우리의 qualitative experiments를 위해. 2개의 subjects는 1151와 1635 frames를 갖는다, 각각, training을 위해.
Pose Metrics.
우리는 PA-MPJPE metric을 보고한다, 이것은 test set에서 전체 frames에 걸쳐 Procrustes-aligned(PA) predictions과 ground truth 3D joint position averaged간의 Euclidean distance이다. PA alignment in scale and orientation은 knowledge of the ground truth calibration를 가정하지 않는 approaches들과 비교를 위해 필수적이다. 다음 이전 연구 [26,25,38]에 따라, 우리는 또한 MPI-INF-3DHP에 대해서 percentange of correct keypoints (PCK)를 보고한다; ground truth와 150mm이내의 거리에 있는 joints의 percentage
Visual Metrics.
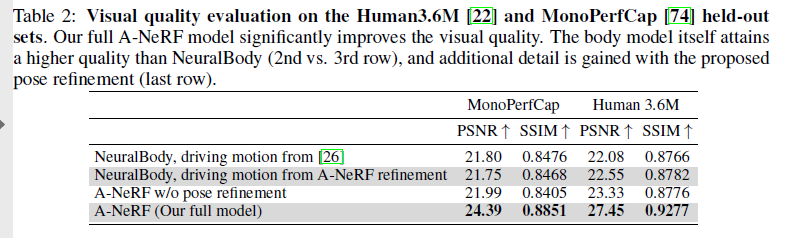
우리는 subset에 대한 training과 동일한 character의 held-out test set에서 testing하여 MonoPerfCap 및Human 3.6M datasets에 대한 isual quality을 정량화한다. Image quality는 character bounding boxes안에 reference image랑 비교하여 rendering의 PSNR과 SSIM을 통해 정량화된다. 이 datasets에 요구되는 skeleton format에 사용가능한 ground truth pose가 없기 때문에, 우리는 신뢰할 수 있는 skeleton pose estimates를 pseudo ground truth로 얻기 위해 전체 dataset에서 모델을 한 번 train 하고 visual quality evaluation를 위해 body model을 학습하기 위해 보류된 part를 사용하여 두 번째 learn을 실시한다.
MonoPerfCap은 actor당 하나의 sequence를 갖기 때문에, 우리는 각 video당 마지막 20%는 배제한다.
Human 3.6M에대해서, 우리는 이름이 Geeting-1,2, Posing-1,2, Walking-1,2인 전체 actions를 제외한다. 그런 다음 body model은 pseudo ground truth poses를 driving motion으로 사용하여 held-out portion으로 전환된다. 그렇게해서, 우리는 dataset에 제공된 underlying skeleton model에 관계없이 새로운 poses와 viewpoints에 대한 다양한 models의 일반화를 테스트할 수 있다.
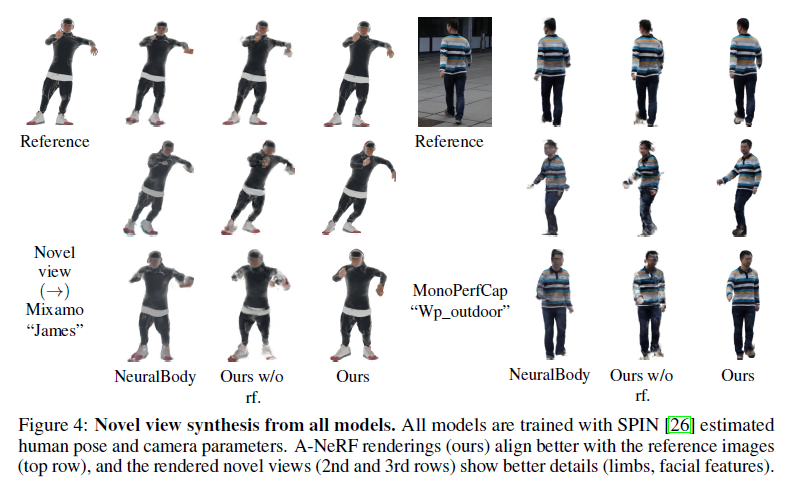
Novel-View-Synthesis and Character Animation.

Human Pose Estimation.
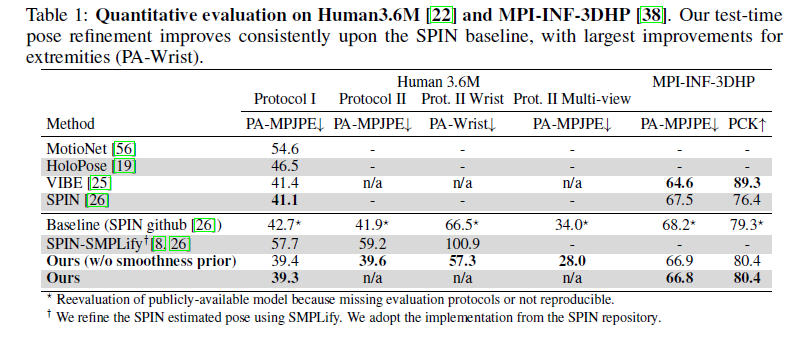
Training A-NeRF는 test-time optimization의 form(Figure1,right참고)을 포함한다, 또한 [26]에서 initialization은 Human3.6M training set에 supervised train된다. Table1은 Human3.6M에 대해 보여준다, A-NeRF는 다른 single-view approaches에 대해 comparable results에 도달하고, Protocol I (42.7 -> 39.3) 그리고 Protocol II (41.9 -> 39.6)에 pose initialization으로 사용되는 baseline의 PA-MPJPE에서 8.0%의 향상을 성취하였다.
…
A-NeRF는 서로 다른 images에서 3D body representation 중에 disagreement를 implicitly minimizing함으로써 poses를 optimize한다. 그래서 더 좋은 성과를 성취한다.
MPI-INF-3DHP에서, Table 1은 MPI-INF-3DHPdptj 6개의 test subjects의 평균 결과를 보여준다.
skeleton-relative encoding을 learning하는 데 사용할 수 있는 frames와 human poses의 수가 적음에도 불구하고, A-NeRF는 여전히 baseline estimations에 비해 moderate improvements을 제공한다.
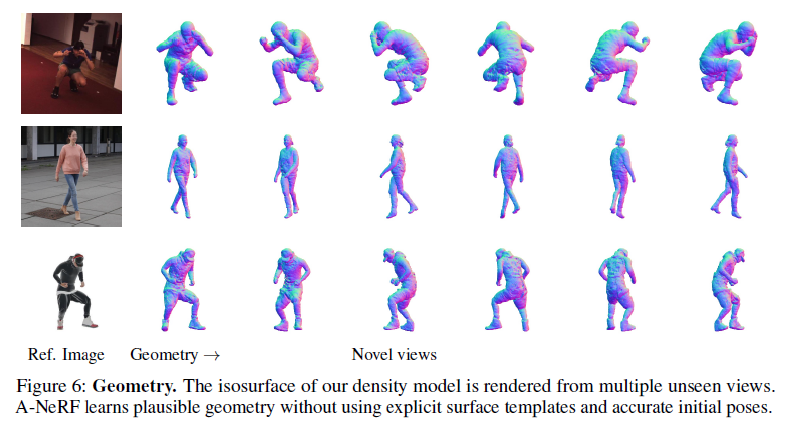
Video-based volumetric reconstruction.
Multi-view extension.
Visual Quality Comparison.

Ablation study.
Limitations and Failure Cases.
Conclusion
우리는 articulated skeleton models와 implicit functions을 overcomplete re-parametrization를 통해 integrating하는 새로운 방법을 제안한다. 이것은 2D images에서 interpretable 3D representation을 learning하는것을 포함한다; a personalized volumetric density field with texture detail and time-varying poses of the actor depicted in the input.
single query location에서 multiple parts로 매핑하는 underlying ill-posed problem는 overparametrization over nearby parts로 다뤄진다.
우리가 알기로는, A-NeRF는 unconstrained video에서 extreme하고 articulated한 motion을 NeRF models로 정의한 첫 approach이다. 그리고 이 새 approach는 Human 3.6M benchmark에 대해 높은 점수를 매겼다. 중요하게, 이것은 single video에서 작동하며 자연스럽게 multi-view까지 확장되고 어떤 scenario에서 camera calibration을 요구하지 않는다. 이것은 motion capture를 더 정확하고 실용적으로 만드는 중요한 단계이다. 미래에는, 우리는 개별적으로 말고 subjects의 database로 부터 general human model을 학습할 것이다.