Anomaly Detection(이상 탐지)
제 1회 KUIAI 대회

졸업전 산공 친구들과 추억을 쌓기위해 즉흥적으로 지원한 해커톤이였다.
하루만에 끝나는 대회여서 부담이 없었다.
하지만 어떤 데이터로 무엇을 하는지, 대회의 어떤 목표도 모른채 참여하게되었다.
10시부터 12시까지 대회 소개 및 설명이였는데…
정말 운영진 분들이 처음하는게 느껴졌다. zoom으로 하는데 영상도 안틀어지고, ppt도 보는데 굉장한 시간이 걸렸었다.
참여팀은 대략 20팀? 그중에 탈주한 팀도 있었고….
아마 제대로 한팀은 몇 팀 없었다. 오후 12시에 시작해서 다음날 12시까지 제출로 24시간 타임어택 해커톤인데. 11시45분까지 제출한팀이 2팀뿐이였다.
주관 및 지원은 고려대학교, 사람투자, 한국산업기술진흥원, 한국전자기술연구원 이였다.
Hackathon:
Anomaly Detection(이상 탐지) in industrial envirioment
대회 당일 홈페이지를 알려주었다.
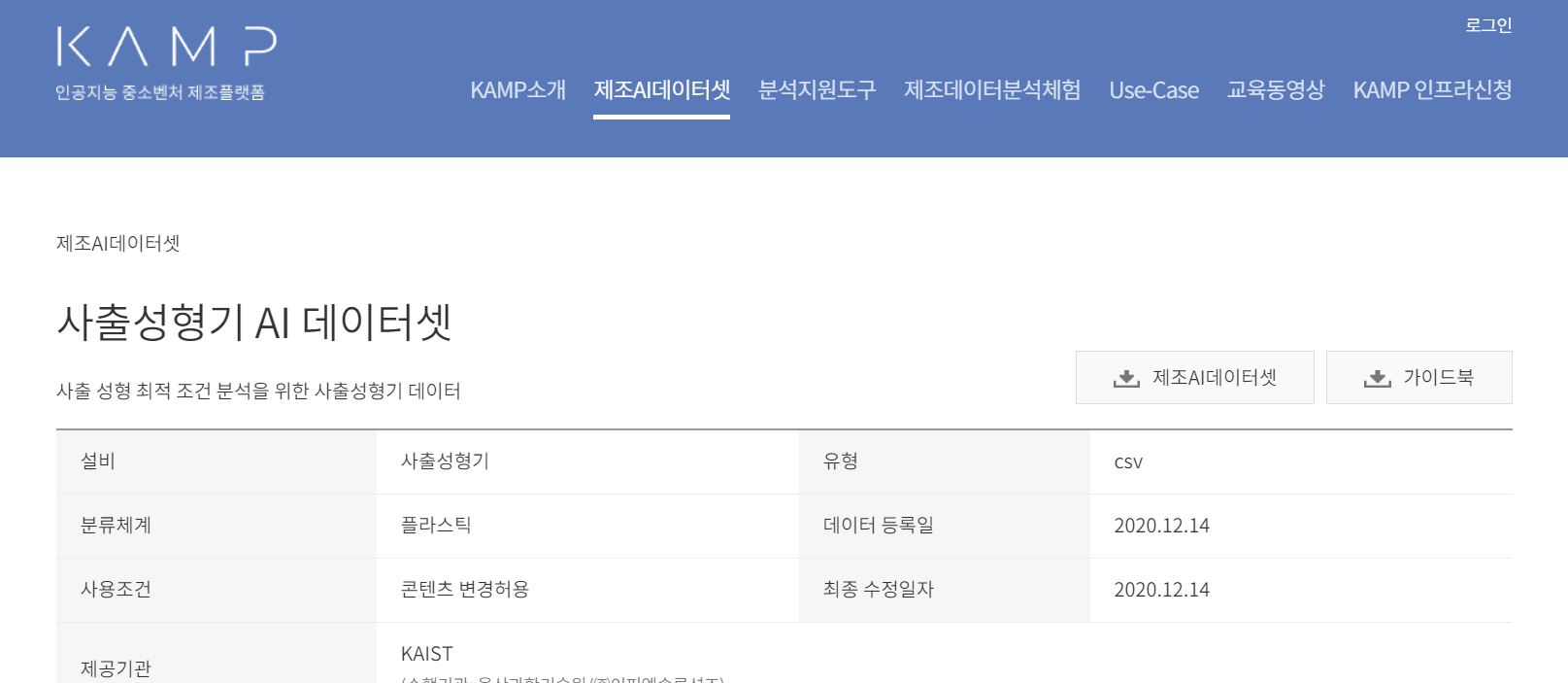
데이터셋에는 코드도 들어있고 csv 데이터도 들어있었다.
처음부터 하는것이 아니고 주어진 데이터를 수정하는거라서 다행이다 느꼈었다…처음에는
가이드북은 정말 세세하게 개념과 목표 이유, 데이터 소개, 코드 설명등 꼼꼼히 되어있었다.
여기서 제조 AI 데이터셋 목록에 사출성형기 AI 데이터셋, 용해탱크 AI 데이터셋을 다운받고 데이터를 분석한 다음 3가지 목표를 이루는 것이였다.
높은 검출 성능
빠른 학습 및 판단속도
가벼운 모델크기
1. Industiral Artificial Inteligence
1.1 Autonomous factory
1.2 제조 AI 및 스마트공장 적용 현실
주제는 크게 Industrial Artificial Inteligence로 IAI분야에서 Autonomous factory가 1차, 2차, 3차 산업혁명을 거치고 4차 산업혁명에서 Connectivity와 Benefits, Technology, Investment 관점에서 설명을 들었었다.
현재 인공지능의 발전으로 여러 이론을 대입하여 공장에 적용하였지만 제조 AI및 스마트공장 적용 현실은 항상 완벽하지 못하고 있고 ceo는 그 성능에 실망하고 AI 도입을 철회하거나 미룬다고 하였다.
2. Industiral AI Problem
2.1 라벨링 데이터의 부제
2.2 데이터 불균형의 문제
2.3 컴퓨터 성능 및 제조환경문제
2.4 검출 성능 문제
2.1 라벨링 데이터의 부제
좋은 머신러닝 모델을 만드려면 높은 수준의 학습 데이터가 필요
산업 현장 데이터는 자동으로 방대한 데이터가 쏟아지기 때문에 데이터를 라벨링하기가 어려움
2.2 데이터 불균형의 문제
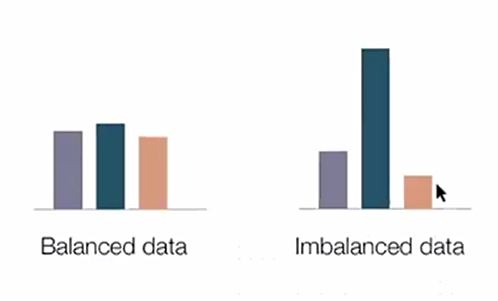
라벨링을 어렵게 진행하더라도 데이터 불균형의 문제 발생
대부분의 공장 및 설비는 정상동작을 수행함
비정상 사례가 발생하는 빈도수가 극히 낮음
비정상 사례가 발생하더라도 발생 시각 및 유형을 선별하고 데이터로 저장하기 ㅇ려움
2.3 컴퓨터 성능 및 제조환경문제
딥러닝 기반 모델 학습 시 학습시간이 오랴 ㄱㄹ림
공정이 변화되거나 센서 부착위치가 변경되면 재학습이 필요
센서/설비 별 학습모델이 관리되어야 하는데 모델의 크기가 클 경우 컴퓨팅 용량문제가 발생할수 있음
학습시간 및 판단시간이 느리면 실제 서비스에서 활용되기 어려움에
실 적용가능한 AI는 학습 및 판단속도가 굉장히 빠르고 모델의 용량도 가벼워야함
2.4 검출 성능 문제
산업현장에서는 검출결과에 따른 설비정지/정비가 이뤄지기 때문에 검출성능이 아주 좋아야 실제 적용 가능
검출성능이 좋지 못하면 생산성 저하 및 점검 시간 증대로 역효과 발생 가능성이 높음
3. Anomaly Detection
3.1 Anomaly Detection
3.2 Anomaly Detection Method
3.3 Outlier Detection / Novelty Detection
3.1 Anomaly Detection
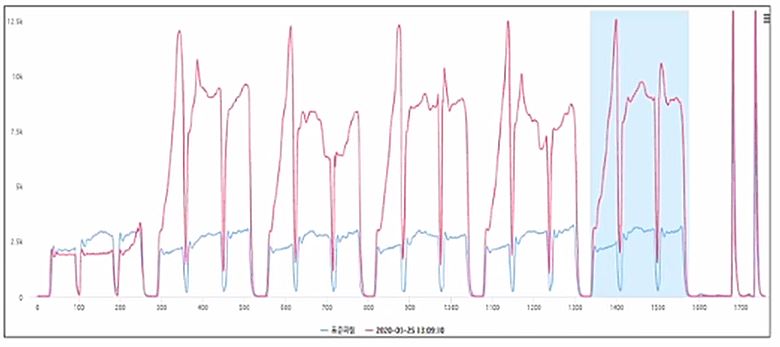

제조 현장에서 이상감지는 설비의 이상을 감지하거나 생산제품 또는 제조환경의 이상을 감지하는 것을 의미함
대부분 정상가공 또는 정상상태이지만, 특정상황에서 이상이 발생되고 이는 자동화라인 정지, 연속 불량 생산 등의 심대한 손해를 발생시킴
3.2 Anomaly Detection Method
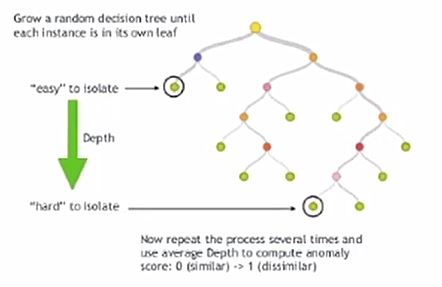
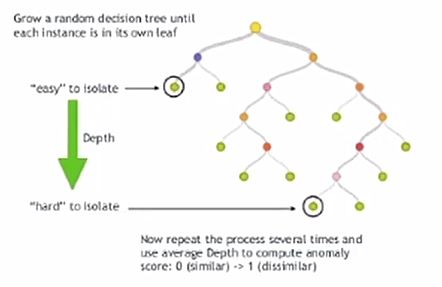
- Tree-based: Isolation-forest
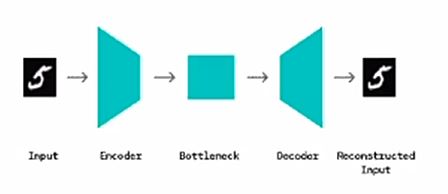
- Reconstruct-based: AutoEncoder
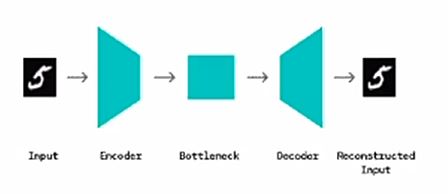
- SVM-based: One-class SVM
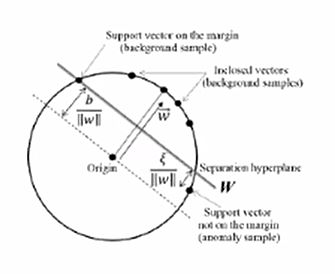
3.3 Outlier Detection / Novelty Detection
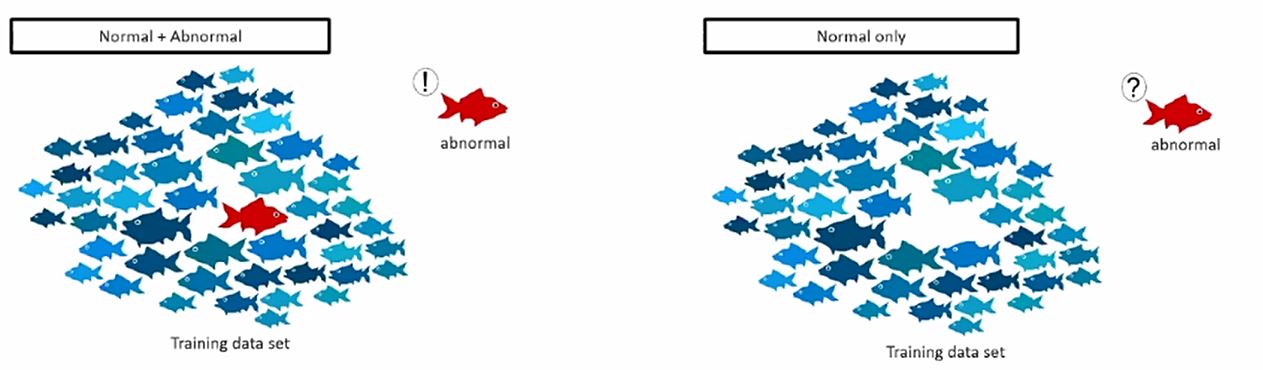
- Semi-Supervised (Novelty Detection)
- Only nomarl data available to train
- normal data only
- Unsupervised (Outlier Detection)
- no labels
- nomarl + abnormal data
실 산업현장에서 얻은 데이터는 실제 데이터셋이 Novelty 환경인 경우가 많음 (정상만 있는 데이터 셋)
- 정상만 있는 데이터 셋에서 불량을 검출하는 경우에는 Isolation Forest등의 알고리즘 검출 성능이 좋지 않음
4. Goal
High-performance Anomaly Detection in Nobelty
- 주어진 데이터 셋에서 정상만 가지고 학습한 뒤 정상/비정상을 판단
- 데이터의 특성(다중클래스, 초코차원 데이터)에 따라 각기 다른 결과물이 나오기 때문에 데이터의 특성 분석 필요
신규 알고리즘을 개발(통계기반, 머신러닝, 딥러닝 상관없음)하거나, 기존 Anomaly Detection에 활용되는 알고리즘 조합 및 프로세스 변경 등의 다양한 접근
- 목표
높은 검출 성능
빠른 학습 및 판단속도
가벼운 모델크기
3가지를 목표로 최대한의 결과 도출
- 검증방법
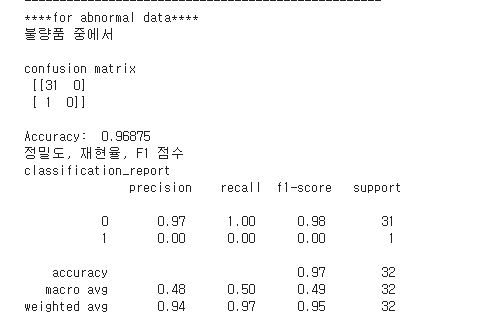
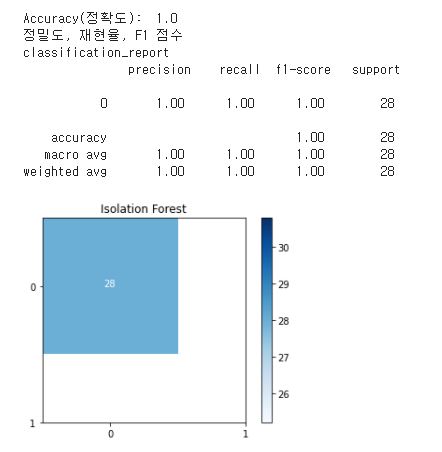
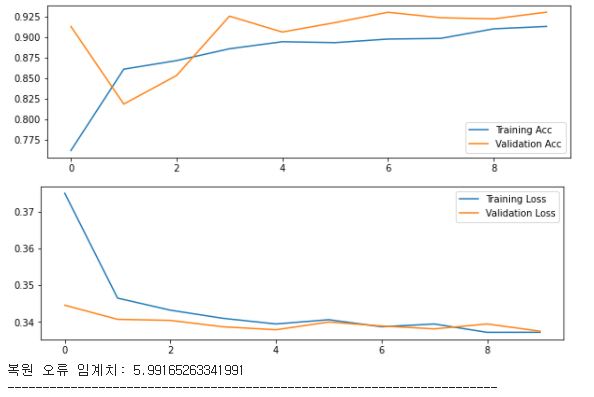
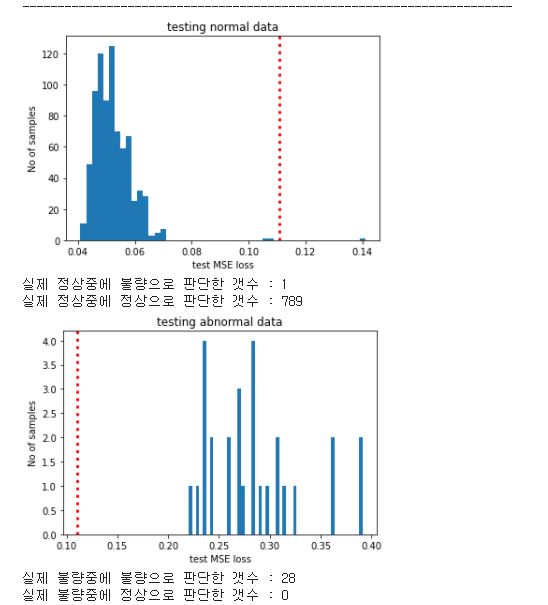
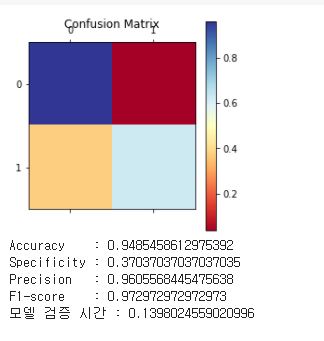
- 검출검증 : 적용 알고리즘의 AUROC 수치, 언노멀 스코어 시각화, 혼동행렬(Confusion Matrix) 등으로 성능 검증
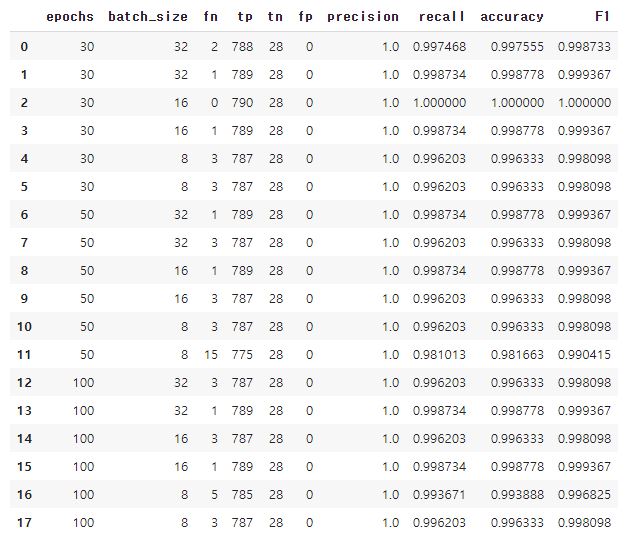
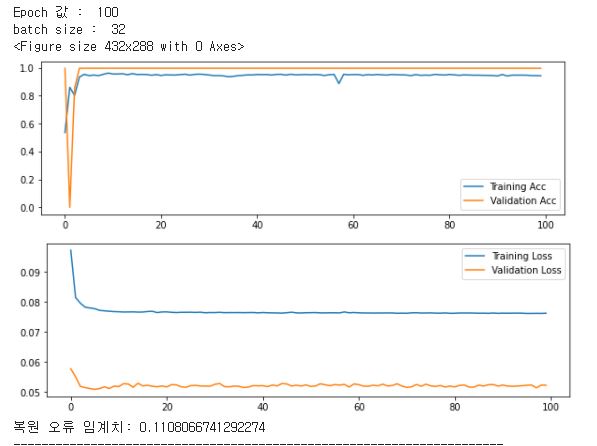
- 속도검증 : 학습 데이터 수량, 데이터 차원, 컴퓨터자원(CPU,RAM)을 명시하고 학습시간과 예측시간으로 성능검증
- 모델크기 : 필수 검증사항은 아니지만, 학습된 모델의 크기를 표시
결론
어려웠다… 이쪽분야를 전혀 모르고 있었다.
새로 배운게 많고 느슨했던 나의 열정이 다시 깨어난거 같다.
PCA, SVM, AutoEncoder, Anomaly Detection, Outlier Detection / Novelty Detection, Isolation-forest, Minimum Covariance Determinant Method 등 배워야할게 많아졌다.
코드공유



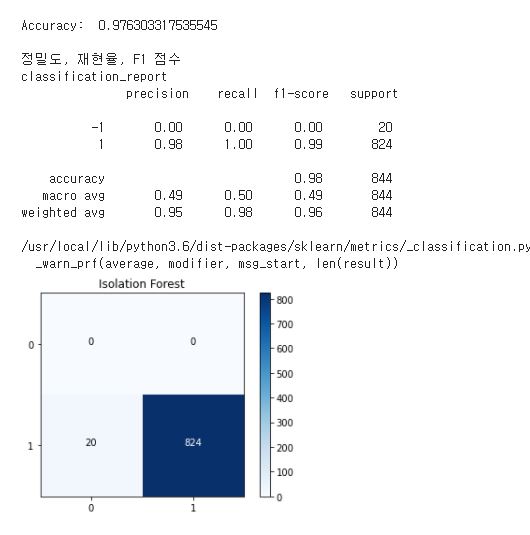
공부해야할 블로그
https://gaussian37.github.io/ml-concept-ml-evaluation/#roc%EC%99%80-auc-1