Large-scale Point Cloud Semantic Segmentation with Superpoint Graphs
.
CVPR 2018 paper
Abstract
We propose a novel deep learning-based framework to tackle the challenge of semantic segmentation of largescale point clouds of millions of points.
We argue that the organization of 3D point clouds can be efficiently captured by a structure called superpoint graph (SPG), derived from a partition of the scanned scene into geometrically homogeneous elements.
SPGs offer a compact yet rich representation of contextual relationships between object parts, which is then exploited by a graph convolutional network.
Our framework sets a new state of the art for segmenting outdoor LiDAR scans (+11.9 and +8.8 mIoU points for both Semantic3D test sets), as well as indoor scans (+12.4 mIoU points for the S3DIS dataset).
1. Introduction
Semantic segmentation of large 3D point clouds presents numerous challenges, the most obvious one being the scale of the data. Another hurdle is the lack of clear structure akin to the regular grid arrangement in images. These obstacles have likely prevented Convolutional Neural Networks (CNNs) from achieving on irregular data the impressive performances attained for speech processing or images.
Previous attempts at using deep learning for large 3D data were trying to replicate successful CNN architectures used for image segmentation. For example, SnapNet [5] converts a 3D point cloud into a set of virtual 2D RGBD snapshots, the semantic segmentation of which can then be projected on the original data. SegCloud [44] uses 3D convolutions on a regular voxel grid. However, we argue that such methods do not capture the inherent structure of 3D point clouds, which results in limited discrimination performance. Indeed, converting point clouds to 2D format comes with loss of information and requires to perform surface reconstruction, a problem arguably as hard as semantic segmentation. Volumetric representation of point clouds is inefficient and tends to discard small details.
Deep learning architectures specifically designed for 3D point clouds [37, 43, 40, 38, 10] display good results, but are limited by the size of inputs they can handle at once.
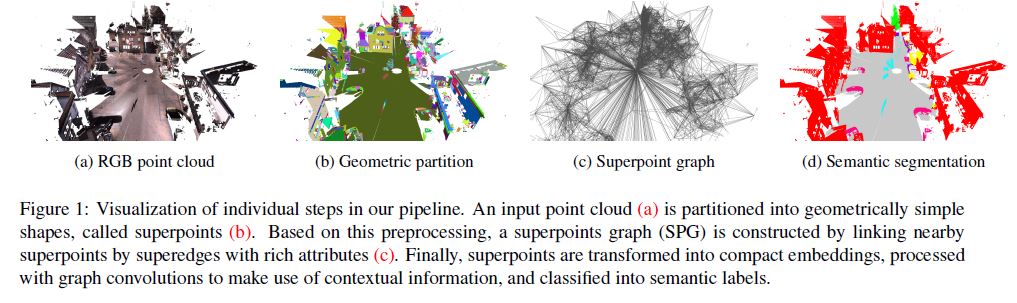
We propose a representation of large 3D point clouds as a collection of interconnected simple shapes coined superpoints, in spirit similar to superpixel methods for image segmentation [1]. As illustrated in Figure 1, this structure can be captured by an attributed directed graph called the superpoint graph (SPG). Its nodes represent simple shapes while edges describe their adjacency relationship characterized by rich edge features.
The SPG representation has several compelling advantages. First, instead of classifying individual points or voxels, it considers entire object parts as whole, which are easier to identify. Second, it is able to describe in detail the relationship between adjacent objects, which is crucial for contextual classification: cars are generally above roads, ceilings are surrounded by walls, etc. Third, the size of the SPG is defined by the number of simple structures in a scene rather than the total number of points, which is typically several order of magnitude smaller. This allows us to model long-range interaction which would be intractable otherwise without strong assumptions on the nature of the pairwise connections. Our contributions are as follows:
We introduce superpoint graphs, a novel point cloud representation with rich edge features encoding the contextual relationship between object parts in 3D point clouds.
Based on this representation, we are able to apply deep learning on large-scale point clouds without major sacrifice in fine details.
Our architecture consists of Point-Nets [37] for superpoint embedding and graph convolutions for contextual segmentation. For the latter, we introduce a novel, more efficient version of Edge-Conditioned Convolutions [43] as well as a new form of input gating in Gated Recurrent Units [8].We set a new state of the art on two publicly available datasets: Semantic3D [14] and S3DIS [3]. In particular, we improve mean per-class intersection over union (mIoU) by 11.9 points for the Semantic3D reduced test set, by 8.8 points for the Semantic3D full test set, and by up to 12.4 points for the S3DIS dataset.
2. Related Work
The classic approach to large-scale point cloud segmentation is to classify each point or voxel independently using handcrafted features derived from their local neighborhood [46]. The solution is then spatially regularized using graphical models [35, 22, 32, 42, 20, 2, 36, 33, 47] or structured optimization [25]. Clustering as preprocessing [16, 13] or postprocessing [45] have been used by several frameworks to improve the accuracy of the classification.
Deep Learning on Point Clouds.
Several different approaches going beyond naive volumetric processing of point clouds have been proposed recently, notably setbased [37, 38], tree-based [40, 21], and graph-based [43]. However, very few methods with deep learning components have been demonstrated to be able to segment large-scale point clouds. PointNet [37] can segment large clouds with a sliding window approach, therefore constraining contextual information within a small area only. Engelmann et al. [10] improves on this by increasing the context scope with multi-scale windows or by considering directly neighboring window positions on a voxel grid. SEGCloud [44] handles large clouds by voxelizing followed by interpolation back to the original resolution and post-processing with a conditional random field (CRF). None of these approaches is able to consider fine details and long-range contextual information simultaneously. In contrast, our pipeline partitions point clouds in an adaptive way according to their geometric complexity and allows deep learning architecture to use both fine detail and interactions over long distance.
Graph Convolutions.
A key step of our approach is using graph convolutions to spread contextual information. Formulations that are able to deal with graphs of variable sizes can be seen as a form of message passing over graph edges [12]. Of particular interest are models supporting continuous edge attributes [43, 34], which we use to represent interactions. In image segmentation, convolutions on graphs built over superpixels have been used for postprocessing: Liang et al. [30, 29] traverses such graphs in a sequential node order based on unary confidences to improve the final labels. We update graph nodes in parallel and exploit edge attributes for informative context modeling. Xu et al. [48] convolves information over graphs of object detections to infer their contextual relationships. Our work infers relationships implicitly to improve segmentation results. Qi et al. [39] also relies on graph convolutions on 3D point clouds. However, we process large point clouds instead of small RGBD images with nodes embedded in 3D instead of 2D in a novel, rich-attributed graph. Finally, we note that graph convolutions also bear functional similarity to deep learning formulations of CRFs [49], which we discuss more in Section 3.4.
3. Method
The main obstacle that our framework tries to overcome is the size of LiDAR scans. Indeed, they can reach hundreds of millions of points, making direct deep learning approaches intractable. The proposed SPG representation allows us to split the semantic segmentation problem into three distinct problems of different scales, shown in Figure 2, which can in turn be solved by methods of corresponding complexity:
Geometrically homogeneous partition:
The first step of our algorithm is to partition the point cloud into geometrically simple yet meaningful shapes, called superpoints. This unsupervised step takes the whole point cloud as input, and therefore must be computationally very efficient. The SPG can be easily computed from this partition.Superpoint embedding:
Each node of the SPG corresponds to a small part of the point cloud corresponding to a geometrically simple primitive, which we assume to be semantically homogeneous. Such primitives can be reliably represented by downsampling small point clouds to at most hundreds of points. This small size allows us to utilize recent point cloud embedding methods such as PointNet [37].Contextual segmentation:
The graph of superpoints is by orders of magnitude smaller than any graph built on the original point cloud. Deep learning algorithms based on graph convolutions can then be used to classify its nodes using rich edge features facilitating longrange interactions.
The SPG representation allows us to perform end-to-end learning of the trainable two last steps. We will describe each step of our pipeline in the following subsections.
3.1. Geometric Partition with a Global Energy
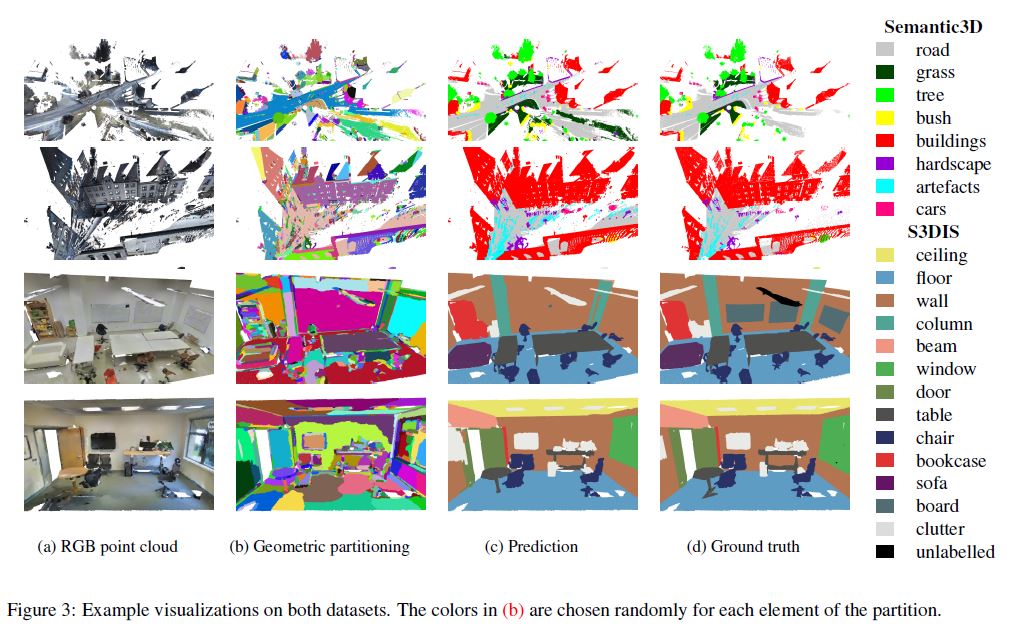
In this subsection, we describe our method for partitioning the input point cloud into parts of simple shape. Our objective is not to retrieve individual objects such as cars or chairs, but rather to break down the objects into simple parts, as seen in Figure 3. However, the clusters being geometrically simple, one can expect them to be semantically homogeneous as well, i.e. not to cover objects of different classes. Note that this step of the pipeline is purely unsupervised and makes no use of class labels beyond validation.
We follow the global energy model described by [13] for its computational efficiency. Another advantage is that the segmentation is adaptive to the local geometric complexity. In other words, the segments obtained can be large simple shapes such as roads or walls, as well as much smaller components such as parts of a car or a chair.
Let us consider the input point cloud \(C\) as a set of \(n\) 3D points.
Each point \(i \in C\) is defined by its 3D position \(p_i\), and, if available, other observations \(o_i\) such as color or intensity. For each point, we compute a set of \(d_g\) geometric features \(f_i \in R^{d_g}\) characterizing the shape of its local neighborhood. In this paper, we use three dimensionality values proposed by [9]: linearity, planarity and scattering, as well as the verticality feature introduced by [13]. We also compute the elevation of each point, defined as the z coordinate of \(p_i\) normalized over the whole input cloud.
The global energy proposed by [13] is defined with respect to the 10-nearest neighbor adjacency graph \(G_{nn} = (C,E_{nn})\) of the point cloud (note that this is not the SPG). The geometrically homogeneous partition is defined as the constant connected components of the solution of the following optimization problem: \[\arg \min_{g \in \mathbb{R^{d_g}}} \sum_{i \in C}||g_i - f_i||^2 + \mu \sum_{(i,j) \in E_nn} w_{i,j}[g_i - g_j \ne 0] \qquad (1)\]
,where [·] is the Iverson bracket. The edge weight \(w \in \mathbb{R}^{|E|}_{+}\) is chosen to be linearly decreasing with respect to the edge length.
The factor \(μ\) is the regularization strength and determines the coarseness of the resulting partition.
The problem defined in Equation 1 is known as generalized minimal partition problem, and can be seen as a continuous-space version of the Potts energy model, or an \(ℓ_0\) variant of the graph total variation. The minimized functional being nonconvex and noncontinuous implies that the problem cannot realistically be solved exactly for large point clouds. However, the \(ℓ_0\)-cut pursuit algorithm introduced by [24] is able to quickly find an approximate solution with a few graph-cut iterations. In contrast to other optimization methods such as α-expansion [6], the \(ℓ_0\)-cut pursuit algorithm does not require selecting the size of the partition in advance. The constant connected components \(S = \{S_1, · · · , S_k\}\) of the solution of Equation 1 define our geometrically simple elements, and are referred as super-points (i.e. set of points) in the rest of this paper.

3.2. Superpoint Graph Construction
In this subsection, we describe how we compute the SPG as well as its key features. The SPG is a structured representation of the point cloud, defined as an oriented attributed graph \(\mathcal{G} = (\mathcal{S}, \mathcal{E}, F)\) whose nodes are the set of superpoints \(\mathcal{S}\) and edges \(\mathcal{E}\) (referred to as superedges) represent the adjacency between superpoints. The superedges are annotated by a set of \(d_f\) features: \(F \in \mathbb{R}^{\epsilon × d_f}\) characterizing the adjacency relationship between superpoints.
We define \(G_{vor} = (C,E_{vor})\) as the symmetric Voronoi adjacency graph of the complete input point cloud as defined by [19]. Two superpoints \(S\) and \(T\) are adjacent if there is at least one edge in \(E_{vor}\) with one end in \(S\) and one end in \(T\): \[\mathcal{E} = \{(S, T) \in S^2 | ∃ (i, j) \in E_{vor} ∩ (S × T)\}. \qquad (2)\]
Important spatial features associated with a superedge (S, T) are obtained from the set of offsets \(δ(S, T)\) for edges in \(E_{vor}\) linking both superpoints: \[δ (S, T) = \{(p_i − p_j) | (i, j) ∈ E_{vor} ∩ (S × T)\} \qquad (3)\]
| Superedge features can also be derived by comparing the shape and size of the adjacent superpoints. To this end, we compute $$ | S | \(as the number of points comprised in a superpoint\)S\(, as well as shape features length\)(S) = λ_1\(, surface\)(S) = λ_1λ_2\(, volume\)(S) = λ_1λ_2λ_3\(derived from the eigenvalues\)λ_1, λ_2, λ_3$$ of the covariance of the positions of the points comprised in each superpoint, sorted by decreasing value. In Table 1, we describe a list of the different superedge features used in this paper. Note that the break of symmetry in the edge features makes the SPG a directed graph. |
3.3. Superpoint Embedding
The goal of this stage is to compute a descriptor for every superpoint Si by embedding it into a vector zi of fixed-size dimensionality dz. Note that each superpoint is embedded in isolation; contextual information required for its reliable classification is provided only in the following stage by the means of graph convolutions.
Several deep learning-based methods have been proposed for this purpose recently. We choose PointNet [37] for its remarkable simplicity, efficiency, and robustness. In PointNet, input points are first aligned by a Spatial Transformer Network [18], independently processed by multilayer perceptrons (MLPs), and finally max-pooled to summarize the shape.
In our case, input shapes are geometrically simple objects, which can be reliably represented by a small amount of points and embedded by a rather compact PointNet. This is important to limit the memory needed when evaluating many superpoints on current GPUs. In particular, we subsample superpoints on-the-fly down to \(n_p = 128\) points to maintain efficient computation in batches and facilitate data augmentation. Superpoints of less than \(n_p\) points are sampled with replacement, which in principle does not affect the evaluation of PointNet due to its max-pooling. However, we observed that including very small superpoints of less than \(n_{minp} = 40\) points in training harms the overall performance. Thus, embedding of such superpoints is set to zero so that their classification relies solely on contextual information.
In order for PointNet to learn spatial distribution of different shapes, each superpoint is rescaled to unit sphere before embedding. Points are represented by their normalized position \(p^′_i\), observations \(o_i\), and geometric features \(f_i\) (since these are already available precomputed from the partitioning step). Furthermore, the original metric diameter of the superpoint is concatenated as an additional feature after PointNet max-pooling in order to stay covariant with shape sizes.
3.4. Contextual Segmentation
The final stage of the pipeline is to classify each superpoint \(S_i\) based on its embedding \(\mathbf{z}_i\) and its local surroundings within the SPG. Graph convolutions are naturally suited to this task. In this section, we explain the propagation model of our system.
Our approach builds on the ideas from Gated Graph Neural Networks [28] and Edge-Conditioned Convolutions (ECC) [43]. The general idea is that superpoints refine their embedding according to pieces of information passed along superedges. Concretely, each superpoint Si maintains its state hidden in a Gated Recurrent Unit (GRU) [8]. The hidden state is initialized with embedding \(\mathbf{z}_i\) and is then processed over several iterations (time steps) \(t = 1 . . . T\). At each iteration \(t\), a GRU takes its hidden state \(h^{(t)}_i\) and an incoming messagem \(\mathbf{m}^{(t)}_i\) as input, and computes its new hidden state \(h^{(t+1)}_i\) . The incoming messagem \(m^{(t)}_i\) i to superpoint \(i\) is computed as a weighted sum of hidden states \(h^{(t)}_j\) of neighboring superpoints \(j\). The actual weighting for a superedge \((j, i)\) depends on its attributes \(F_{ji}\),·, listed in Table 1. In particular, it is computed from the attributes by a multi-layer perceptron \(\Theta\), so-called Filter Generating Network. Formally:
\(\mathbf{h}^{t+1}_i = (1-\mathbf{u}^{(t)}_i) \odot \mathbf{q}^{(t)}_i + \mathbf{u}^{(t)}_i \odot \mathbf{h}^{(t)}_i\)
\(\mathbf{q}^{t}_i = tanh(\mathbf{x}^{(t)}_{1,i} + \mathbf{r}^{(t)}_i \odot \mathbf{h}^{(t)}_{1,i}) \qquad \qquad (4)\) \(\mathbf{u}^{(t)}_i = \sigma(\mathbf{x}^{(t)}_{2,i} + \mathbf{h}^{(h)}_{2,i}), \qquad \mathbf{r}^{(t)}_i = \sigma(\mathbf{x}^{(t)}_{3,i} + \mathbf{h}^{(h)}_{3,i})\)
\((\mathbf{h}^{(t)}_{1,i},\mathbf{h}^{(t)}_{2,i},\mathbf{h}^{(t)}_{3,i})^T = \rho(W_h\mathbf{h}^{(t)}_i + b_h)\) \((\mathbf{x}^{(t)}_{1,i},\mathbf{x}^{(t)}_{2,i},\mathbf{x}^{(t)}_{3,i})= \rho(W_x\mathbf{x}^{(t)}_i + b_x) \qquad \quad (5)\) \[\mathbf{x}^{(t)}_{i} = \sigma(W_g\mathbf{h}^{(t)}_{i} + b_g) \odot \mathbf{m}^{(t)}_{i}\qquad \qquad (6)\] \[\mathbf{m}^{(t)}_{i} = mean_{j|(j,i)\in\mathcal{E}}\Theta(F_{ji},.;W_e) \odot \mathbf{h}^{(t)}_{j}\qquad \qquad (7)\] \[\mathbf{h}^{(1)}_i = \mathbf{z}_i, \qquad \mathbf{y}_i = W_o(\mathbf{h}^{(1)}_i,....,\mathbf{h}^{(T+1)}_i)^T, \qquad (8)\]
where \(\odot\) is element-wise multiplication, \(σ(·)\) sigmoid function, and \(W.\) and \(b.\) are trainable parameters shared among all GRUs. Equation 4 lists the standard GRU rules [8] with its update gate \(u^(t)_i\) and reset gate \(r^(t)_i\) . To improve stability during training, in Equation 5 we apply Layer Normalization [4] defined as \(ρ(\mathbf{a}) := (\mathbf{a}−mean(\mathbf{a}))/(std(\mathbf{a}) + \epsilon)\) separately to linearly transformed input \(\mathbf{x}^{(t)}_i\) and transformed hidden state \(\mathbf{h}^{(t)}_i\) , with \(\epsilon\) being a small constant. Finally, the model includes three interesting extensions in Equations 6– 8, which we detail below.
Input Gating.
We argue that GRU should possess the ability to down-weight (parts of) an input vector based on its hidden state. For example, GRU might learn to ignore its context if its class state is highly certain or to direct its attention to only specific feature channels. Equation 6 achieves this by gating message \(\mathbf{m}^{(t)}_i\) by the hidden state before using it as input\(\mathbf{x}^{(t)}_i\) .
Edge-Conditioned Convolution.
ECC plays a crucial role in our model as it can dynamically generate filtering weights for any value of continuous attributes \(F_{ji}\),· by processing them with a multi-layer perceptron \(\Theta\). In the original formulation [43] (ECC-MV), \(\Theta\) regresses a weight matrix to perform matrix-vector multiplication \(\Theta(F_{ji},.;W_e)\mathbf{h}^{(t)}_j\) for each edge. In this work, we propose a lightweight variant with lower memory requirements and fewer parameters, which is beneficial for datasets with few but large point clouds. Specifically, we regress only an edge-specific weight vector and perform element-wise multiplication as in Equation 7 (ECC-VV). Channel mixing, albeit in an edge-unspecific fashion, is postponed to Equation 5. Finally, let us remark that \(\theta\) is shared over time iterations and that self-loops as proposed in [43] are not necessary due to the existence of hidden states in GRUs.
State Concatenation.
Inspired by DenseNet [17], we concatenate hidden states over all time steps and linearly transform them to produce segmentation logits \(y_i\) in Equation 8. This allows to exploit the dynamics of hidden states due to increasing receptive field for the final classification.
Relation to CRFs.
In image segmentation, postprocessing of convolutional outputs using Conditional Random Fields (CRFs) is widely popular. Several inference algorithms can be formulated as (recurrent) network layers amendable to end-to-end learning [49, 41], possibly with general pairwise potentials [31, 7, 26]. While our method of information propagation shares both these characteristics, our GRUs operate on \(d_z\)-dimensional intermediate feature space, which is richer and less constrained than low-dimensional vectors representing beliefs over classes, as also discussed in [11]. Such enhanced access to information is motivated by the desire to learn a powerful representation of context, which goes beyond belief compatibilities, as well as the desire to be able to discriminate our often relatively weak unaries (superpixel embeddings). We empirically evaluate these claims in Section 4.3.
3.5. Further Details
Adjacency Graphs. In this paper, we use two different adjacency graphs between points of the input clouds: \(G_{nn}\) in Section 3.1 and \(G_{vor}\) in Section 3.2. Indeed, different definitions of adjacency have different advantages. Voronoi adjacency is more suited to capture long-range relationships between superpoints, which is beneficial for the SPG. Nearest neighbors adjacency tends not to connect objects separated by a small gap. This is desirable for the global energy but tends to produce a SPG with many small connected components, decreasing embedding quality. Fixed radius adjacency should be avoided in general as it handles the variable density of LiDAR scans poorly.
Training.
While the geometric partitioning step is unsupervised, superpoint embedding and contextual segmentation are trained jointly in a supervised way with cross entropy loss. Superpoints are assumed to be semantically homogeneous and, consequently, assigned a hard ground truth label corresponding to the majority label among their contained points. We also considered using soft labels corresponding to normalized histograms of point labels and training with Kullback-Leibler [23] divergence loss. It performed slightly worse in our initial experiments, though.
Naive training on large SPGs may approach memory limits of current GPUs. We circumvent this issue by randomly subsampling the sets of superpoints at each iteration and training on induced subgraphs, i.e. graphs composed of subsets of nodes and the original edges connecting them. Specifically, graph neighborhoods of order 3 are sampled to select at most 512 superpoints per SPG with more than \(n_{minp}\) points, as smaller superpoints are not embedded. Note that as the induced graph is a union of small neighborhoods, relationships over many hops may still be formed and learned. This strategy also doubles as data augmentation and a strong regularization, together with randomized sampling of point clouds described in Section 3.3. Additional data augmentation is performed by randomly rotating superpoints around the vertical axis and jittering point features by Gaussian noise \(\mathcal{N}(0, 0.01)\) truncated to [−0.05, 0.05].
Testing.
In modern deep learning frameworks, testing can be made very memory-efficient by discarding layer activations as soon as the follow-up layers have been computed. In practice, we were able to label full SPGs at once. To compensate for randomness due to subsampling of point clouds in PointNets, we average logits obtained over 10 runs with different seeds.
4. Experiments
We evaluate our pipeline on the two currently largest point cloud segmentation benchmarks, Semantic3D [14] and Stanford Large-Scale 3D Indoor Spaces (S3DIS) [3], on both of which we set the new state of the art. Furthermore, we perform an ablation study of our pipeline in Section 4.3. Even though the two data sets are quite different in nature (large outdoor scenes for Semantic3D, smaller indoor scanning for S3DIS), we use nearly the same model for both. The deep model is rather compact and 6 GB of GPU memory is enough for both testing and training. We refer to the Supplementary for precise details on hyperparameter selection, architecture configuration, and training procedure. Performance is evaluated using three metrics: per-class intersection over union (IoU), per-class accuracy (Acc), and overall accuracy (OA), defined as the proportion of correctly classified points. We stress that the metrics are computed on the original point clouds, not on superpoints.
4.1. Semantic3D
Semantic3D [14] is the largest available LiDAR dataset with over 3 billion points from a variety of urban and rural scenes. Each point has RGB and intensity values (the latter of which we do not use). The dataset consists of 15 training scans and 15 test scans with withheld labels. We also evaluate on the reduced set of 4 subsampled scans, as common in past work.
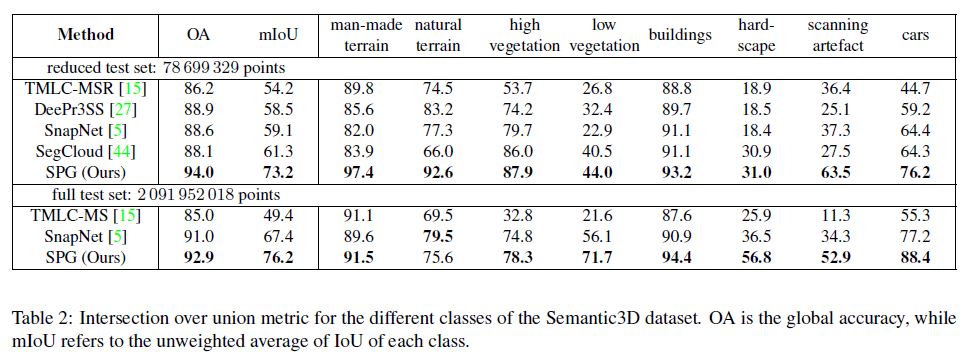
In Table 2, we provide the results of our algorithm compared to other state of the art recent algorithms and in Figure 3, we provide qualitative results of our framework. Our framework improves significantly on the state of the art of semantic segmentation for this data set, i.e. by nearly 12 mIoU points on the reduced set and by nearly 9 mIoU points on the full set. In particular, we observe a steep gain on the “artefact” class. This can be explained by the ability of the partitioning algorithm to detect artifacts due to their singular shape, while they are hard to capture using snapshots, as suggested by [5]. Furthermore, these small object are often merged with the road when performing spatial regularization.
4.2. Stanford LargeScale 3D Indoor Spaces
The S3DIS dataset [3] consists of 3D RGB point clouds of six floors from three different buildings split into individual rooms. We evaluate our framework following two dominant strategies found in previous works. As advocated by [37, 10], we perform 6-fold cross validation with microaveraging, i.e. computing metrics once over the merged predictions of all test folds. Following [44], we also report the performance on the fifth fold only (Area 5), corresponding to a building not present in the other folds. Since some classes in this data set cannot be partitioned purely using geometric features (such as boards or paintings on walls), we concatenate the color information \(o\) to the geometric features \(f\) for the partitioning step.
The quantitative results are displayed in Table 3, with qualitative results in Figure 3 and in the Supplementary. S3DIS is a difficult dataset with hard to retrieve classes such as white boards on white walls and columns within walls. From the quantitative results we can see that our framework performs better than other methods on average. Notably, doors are able to be correctly classified at a higher rate than other approaches, as long as they are open, as illustrated in Figure 3. Indeed, doors are geometrically similar to walls, but their position with respect to the door frame allows our network to retrieve them correctly. On the other hand, the partition merges white boards with walls, depriving the network from the opportunity to even learn to classify them: the IoU of boards for theoretical perfect classification of superpoints (as in Section 4.3) is only 51.3.
Computation Time. In Table 4, we report computation time over the different steps of our pipeline for the inference on Area 5 measured on a 4 GHz CPU and GTX 1080 Ti GPU. While the bulk of time is spent on the CPU for partitioning and SPG computation, we show that voxelization as pre-processing, detailed in Supplementary, leads to a significant speed-up as well as improved accuracy.
4.3. Ablation Studies
To better understand the influence of various design choices made in our framework, we compare it to several baselines and perform an ablation study. Due to the lack of public ground truth for test sets of Semantic3D, we evaluate on S3DIS with 6-fold cross validation and show comparison of different models to our Best model in Table 5.
Performance Limits. The contribution of contextual segmentation can be bounded both from below and above. The lower bound (Unary) is estimated by training PointNet with \(d_z = 13\) but otherwise the same architecture, denoted as PointNet13, to directly predict class logits, without SPG and GRUs. The upper bound (Perfect) corresponds to assigning each superpoint its ground truth label, and thus sets the limit of performance due to the geometric partition. We can see that contextual segmentation is able to win roughly 22 mIoU points over unaries, confirming its importance. Nevertheless, the learned model still has room of up to 26 mIoU points for improvement, while about 12 mIoU points are forfeited to the semantic inhomogeneity of superpoints.
CRFs. We compare the effect of our GRU+ECCbased network to CRF-based regularization. As a baseline (iCRF), we post-process Unary outputs by CRF inference over SPG connectivity with scalar transition matrix, as described by [13]. Next (CRF − ECC), we adapt CRF-RNN framework of Zheng et al. [49] to general graphs with edgeconditioned convolutions (see Supplementary for details) and train it with PointNet13 end-to-end. Finally (GRU13), we modify Best to use PointNet13. We observe that iCRF barely improves accuracy (+1 mIoU), which is to be expected, since the partitioning step already encourages spatial regularity. CRF − ECC does better (+15 mIoU) due to end-to-end learning and use of edge attributes, though it is still below GRU13 (+18 mIoU), which performs more complex operations and does not enforce normalization of the embedding. Nevertheless, the 32 channels used in Best instead of the 13 used in GRU13 provide even more freedom for feature representation (+22 mIoU).
Ablation. We explore the advantages of several design choices by individually removing them from Best in order to compare the framework’s performance with and without them. In NoInputGate we remove input gating in GRU; in NoConcat we only consider the last hidden state in GRU for output as \(y_i = W_o\mathbf{h}^{(T+1)}_i\) instead of concatenation of all steps; in NoEdgeFeat we perform homogeneous regularization by setting all superedge features to scalar 1; and in ECC − VV we use the proposed lightweight formulation of ECC. We can see that each of the first two choices accounts for about 5 mIoU points. Next, without edge features our method falls back even below iCRF to the level of Unary, which validates their design and overall motivation for SPG. ECC − VV decreases the performance on the S3DIS dataset by 3 mIoU points, whereas it has improved the performance on Semantic3D by 2 mIoU. Finally, we invite the reader to Supplementary for further ablations.
5. Conclusion
We presented a deep learning framework for performing semantic segmentation of large point clouds based on a partition into simple shapes. We showed that SPGs allow us to use effective deep learning tools, which would not be able to handle the data volume otherwise. Our method significantly improves on the state of the art on two publicly available datasets. Our experimental analysis suggested that future improvements can be made in both partitioning and learning deep contextual classifiers. The source code in PyTorch as well as the trained models are available at https://github.com/loicland/ superpoint_graph.